Published on: 22 October 2019 |
Last updated: 4 November 2025
On this page
Still wondering how to get Google to crawl your site? Let me summarize all the basics that you want to know about Google crawl budget ahead of talking in-depth about how to optimize crawl budget of your website. This is to ensure that you understand the importance of crawl budget management as one of the key SEO strategies to rank your website on Google.
Another reason for summarizing the important aspects of the search engine’s crawl budget is because getting Google to crawl your site needs technical SEO expertise, and many SEOs skip this due to the cumbersome process of understanding it.
Want to see your website at the top? Don’t let your competitors outshine you. Take the first step towards dominating search rankings and watch your business grow. Get in touch with us now and let’s make your website a star!
What does Crawl Budget Mean?
Google defines crawl budget as the number of pages Googlebot crawls and indexes each time it visits a website. Crawl budget of a website can be influenced by two significant factors, the popularity of the site and the freshness of the content.
A Sneak-Peek into Google’s Crawling Priories
Google wants to cut down on crawling without affecting the crawl quality. There are, indeed, concrete signs about this from Google executives in recent times.
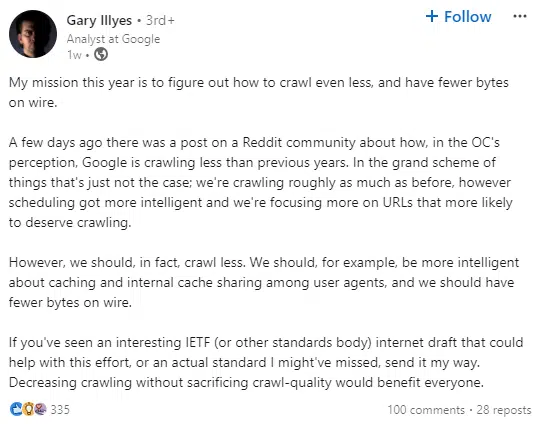
Google Analyst Gary Illyes stated on LinkedIn, “My mission this year is to figure out how to crawl even less.”
This comes in the wake of a Reddit post discussing that Google is crawling less than it did in previous years.
While Illyes confirms that Google is crawling roughly the same amount of content as it used to, he also highlights that scheduling has gotten more intelligent and that Google is extending its focus on URLs that are more likely to deserve crawling.
This description pretty much aligns with crawl budget optimization that insists on the important pages of your site staying within a limited crawl distance so that the search engine can crawl them frequently.
What Determines Google Crawling Prioritization?
So, Google crawlers have their own priorities. But how does Google decide which content to crawl?
In a recent podcast episode featured in Google Search Central, Google’s Search Relations team delves into how the search engine determines how much content it should crawl.
In the podcast, Illyes explains, “If search demand goes down, then that also correlates to the crawl limit going down.”
In this context, search demand probably means how frequently the users search for a particular key term or a topic. So, if there is a dip in user search for a particular key term or topic, Google is less likely to crawl pages related to that topic.
He also adds, “If you want to increase how much we crawl, then you somehow have to convince search that your stuff is worth fetching.”
While Illyes doesn’t expand on how you can do that, it may possibly be making sure that your content stays up to date so that it is helpful and relevant to users at all times.
Now, that brings us to content quality.
How Does Content Quality Influence Google’s Crawling Priorities?
Google has raised the bar for quality and this does impact the search engine’s crawling priorities as well.
Illyes explains, “As soon as we get the signals back from search indexing that the quality of the content has increased across this many URLs, we would just start turning up demand.”
With the demand going up, Google will crawl the corresponding pages more often than before.
In a nutshell, improving the content quality is key to prompting Google to prioritize crawling your page.
Focus on creating high-quality, helpful content that satisfies user intent and aligns with the search demand in your industry.
Keep track of key trends in your industry and devise a scalable content strategy that can accommodate trending topics at any given point in time. This way, your content will always be relevant and crawl-worthy.
How to Get Google to Crawl Your Site Quickly
Google’s Algorithm is smart enough to crawl almost all pages of a small website; either in one go or within a few day’s time. However, things may not be as easy for websites that have thousands to millions of pages.
If you are running a website with a large database of pages, it becomes imperative to optimize the crawl budget to ensure that the important pages are not skipped by Google while it crawls the site.
Enabling Crawling of Important Pages
You may think this is a prerequisite for any site and how come this has become so important in deciding the crawl budget. In the analysis done over the last few years, I have come to an understanding that not all websites have the same crawl requirements. For a few websites, the tag pages may not serve much of a purpose but for a few, the tag pages may be important. There have been instances wherein the client has approached me with a page that has been completely made no-index.
This is where managing the robot.txt file comes to the picture. It’s easy for smaller websites to manage the robots file manually. However, when it comes to a website with thousands of pages you may require the help of third-party tools to understand whether the important pages are crawled. Some of the most popular tools include DeepCrawl and ScreamingFrog. For large websites, it’s highly recommended to do a thorough crawl check to keep crawling related issues at bay.
Avoid Long Redirect Chains
Google is patient enough to wait for page content despite a few 301 or 302 and this doesn’t affect the crawl rate of websites with very few pages. The search engine giant has confirmed that having long redirect chains makes its crawler spent more resources on a single page and this is not something that goes well with Google’s crawler.
The crawler may skip the site from the crawl or end up indexing fewer pages if it finds a large number of long redirect chains. Even though it is practically impossible for larger websites to live without redirects, Google suggests limiting it.
Promote HTML Above any Other Format
Google always tries to use the latest and most updated version of the Chrome browser to crawl web pages across the internet. This has made Google far more intelligent in understanding the JavaScript than before. That said, it’s still improving on this end and a complete perfection is still a distance away.
However, the ability of the crawler to handle Flash and XML has definitely better. Using HTML and XML format against JavaScript will have an impact on improving the crawl rate of the website.
Fewer 5xx Errors Means Better Crawl Budget
One of the biggest technical glitches taking crawl rate of websites for a toss is 404, 410, 500 errors. If the Google crawler encounters 5xx status codes while crawling a website, it’s highly unlikely to skip and there is a chance that the crawl budget for the site is reduced considerably. By ensuring that pages are not turning error status, webmasters have to use tools such as Screaming Frog for doing a periodic website audit.
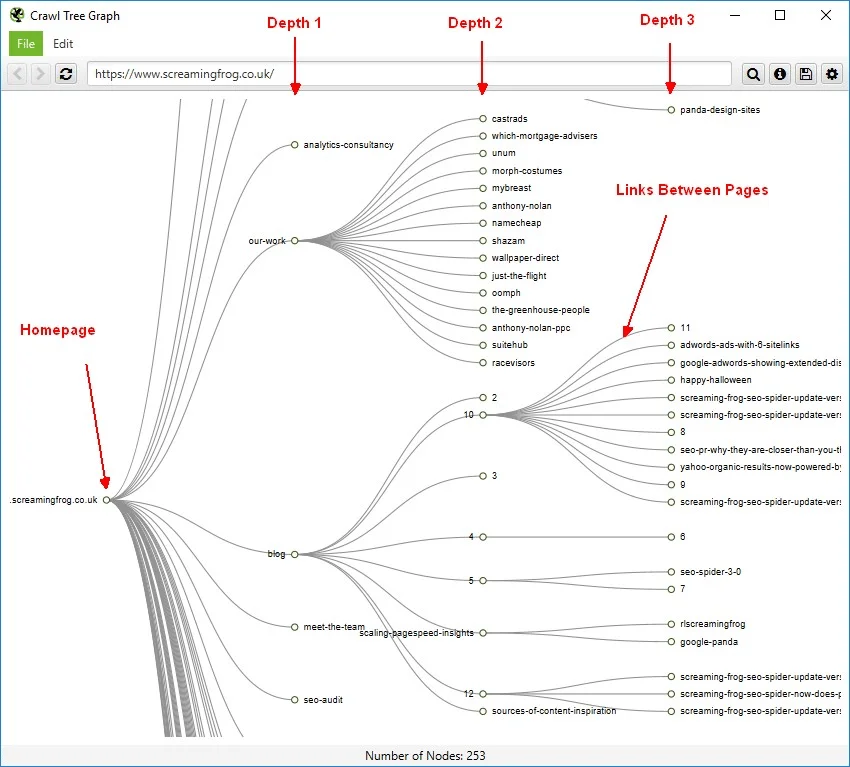
What is Crawl Depth?
Crawl depth refers to the number of links the search engine bot has to crawl through before it reaches a particular page on your website.
It is sometimes known as click depth, which is the measure of the number of clicks the user has to make to reach a specific page on your site.
Crawl depth is usually determined by the number of steps it takes to navigate to a particular page. Most often, the homepage is the starting point.
For instance, a page you can land on directly from the homepage has a minimum crawl depth. On the flip side, a page that requires you to make several clicks across the website to reach it has a comparatively deeper crawl depth.
Why Crawl Depth Matters
Crawl depth strongly relates to user experience and the indexing and ranking of your web pages.
How?
Imagine it this way. If the user has to click through several other pages to access an important page, such as a service page or a product listing page, they may grow impatient and frustrated. This will result in a poor user experience and affect your conversion rate considerably.
Now that’s the same with search engine bots too. If they have to crawl multiple pages before they get to one of your important pages, that may exhaust your site’s crawl budget.
As a result, the important pages on your site may not be crawled and indexed faster by the search engine. This will potentially affect the visibility of your important pages in SERPs.
So, if you haven’t optimized crawl depth, you are compromising on the indexing and ranking potential of your site and user experience, which you most certainly don’t want to do.
Factors that affect crawl depth include poor site structure, improper or broken internal links, lack of XML sitemap implementation and more.
I’ll tell you more about these later in this article.
What Should Be the Ideal Crawl Depth of a Website?
Let’s face the truth. There’s no specific rule of thumb for crawl depth. But here’s the catch.
As a minimum crawl depth makes it easier for web crawlers to locate and crawl your pages, I suggest keeping your priority pages as close to your home as possible.
If you still want a number, it is best to place your important pages at a maximum of 3 clicks away from your homepage.
Considering the crawl depth of your homepage as 0, the best practice is to maintain a crawl depth of 3 or less for the pages you want the search engine to crawl faster.
Also, make sure you add your important pages to the sitemap to signal the search engine to prioritize those pages when crawling your website.
Tips to Improve Crawl Depth
Now that you know how important crawl depth optimization is for your website, here’s a look at some effective tips to put it into action.
Improve Site Structure
A well-structured website with a simple and intuitive design makes it easier for search engine bots to conveniently navigate through your website and crawl your web pages efficiently. This will lead to the indexing and ranking of your content faster by the search engine and boosts its online visibility.
Besides, a simple and attractive website also makes way for a hassle-free user experience and prompts your visitors to dig deeper into your website and explore your content. This will boost user engagement for your site and impact your conversion rate positively.
You can also implement breadcrumb navigation for the search engine and users alike to understand the hierarchy of your site. This too, will contribute to better crawling efficiency and improved user experience.
Analyze and Optimize Your Internal Links
Links within your website are an integral part of crawl depth optimization. After all, Google bots follow links to discover and crawl new pages.
Observing your existing internal linking structure closely will help you narrow down pages that aren’t properly linked to relevant pages within your site. Make sure you use appropriate keywords to create contextual links. When you give your internal links a clear context, you help the search engine to understand your content better.
Speaking of internal links, you don’t want the crawlers to follow one of your links just to find nothing, right? To stop that from happening, you need to fix broken links and ensure that the crawlers are rightly directed to relevant pages.
In case you’ve moved your content to a new URL destination, use 301 redirects to point the crawlers appropriately to the new page.
Prioritize Important Pages
As I mentioned earlier, you don’t want to exhaust your crawl budget before the search engine spiders get to your important pages. That’s why you have to signal them to crawl (or not to crawl) certain pages of your website. It is, of course, a great crawl depth control strategy.
But how do you do that?
One, use robots.txt to specify the pages or directories you don’t want the search engine to crawl. This way, you can extend some control over the crawling behavior of the search engine bots and prompt them to skip pages that don’t need crawling.
Additionally, you can use canonical tags (rel=”canonical”) to prevent the crawlers from wasting the crawl budget on duplicate content.
This will help you reduce crawl depth considerably and the crawl budget can be spent on important pages on your site, such as product/ service pages.
Two, create an effective XML sitemap that contains all your high-value, relevant pages. Unlike robots.txt, the existence of the XML sitemap signals search engines to prioritize pages contained in it when crawling your website.
This ensures that your important pages deliberately attract the attention of the crawlers. Again, as this strategy reduces the focus of the search engine bots on less important pages, it complements crawl depth optimization.
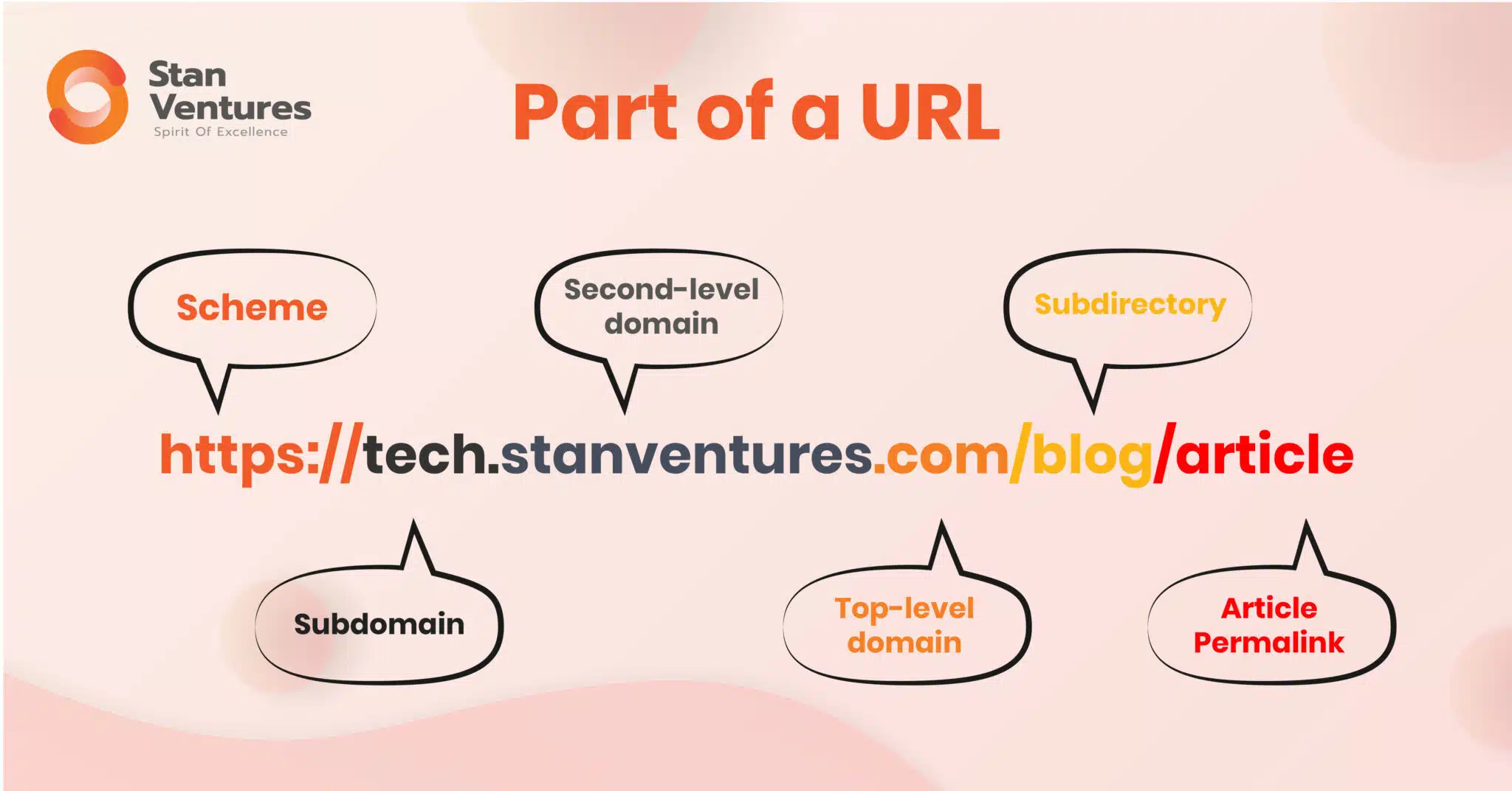
Optimize URL Structure
Keeping your URL depth shallow can make way for an efficient crawl depth optimization.
If you aren’t familiar with URL depth, here’s a quick explanation for you. URL depth denotes the number of directories or subdirectories a URL contains.
Keep your URL depth minimum because search engine crawlers may interpret deeper URLs to be less significant.
A shallow URL structure allows crawlers to easily access and crawl important pages, bolsters crawl depth optimization and ensures that your content is crawled and indexed.
Make sure you keep your URLs short, clear and descriptive. This will help web crawlers to understand your content without crawling extensively.
Also, include relevant keywords in your URL to give it a clear context and improve the visibility of your page in search results.
Smaller image sizes prompt faster loading times. This will enhance crawl depth optimization by ensuring that crawlers can access more pages using the allocated crawl budget.
So, optimize your images by decreasing the size without losing quality. Ensure that you use widely supported image formats like JPEG and PNG.
Yet another way to improve site speed is minifying CSS and JavaScript files by removing unnecessary characters, whitespace, comments and more.
Just like image optimization, this method also comes in handy to minimize file sizes and contributes to a faster page loading time.
Apart from these, ad placements on your site also play a notable role in influencing your site speed. Pop-ups and excessive ads can slow down the page loading speed and affect the crawling process.
That said, make sure you avoid them as much as possible in order to boost crawl efficiency and get more of your pages indexed by the search engine.
How to Perform Crawl Depth Analysis?
So, how do you analyze the crawl depth of your content? I recommend the three ways below.
Using Web Crawling Tools
Web crawling tools, such as Screaming Frog, Moz and Lumar can help you analyze the crawl depth of your website.
These tools allow you to get an overview of the crawl depth of your website, narrow down pages with shallow or deep crawl depth, and evaluate the overall distribution of crawl depth across your web pages.
They help you comprehend how search engine bots view and navigate your site and also provide actionable insights to optimize crawl depth.
Log File Analysis
Log file analysis is the process of evaluating server logs to gain insights into how web crawlers interact with your website.
Using this method, you can identify the crawl depth of your web pages, check for crawl patterns and narrow down potential crawl issues, if any.
Overall, with log file analysis, you get a 360-degree view of how search engine crawlers perceive your site and pin down existing crawling issues to be fixed in order to optimize crawl depth.
Using Google Search Console
The Crawl Stats report in the Google Search Console lets you know Google’s crawl history of your website.
It provides a wide array of crawling statistics, including the number of requests made, kilobytes downloaded, average response time, issues encountered and much more.
With these insights from the Crawl Stats report, you identify similar patterns and potential issues when it comes to crawling your site and take the necessary steps to optimize crawl depth and accelerate the performance of your website.
Future Trends in Crawl Depth Optimization
As AI and machine learning technologies evolve at a pace faster than ever, they are likely to play a significant role in crawl depth optimization. AI-powered systems may potentially be equipped to weigh the website structure, prioritize important pages, and make intelligent decisions on crawl depth.
Over time, machine learning models may transform even better and take part in enhancing crawl efficiency and making sure that search engines focus on crawling high-value, relevant content.
With mobile devices dominating the online space, it’s been some time since search engines shifted to mobile-first indexing.
That said, optimizing crawl depth for mobile content will ensure that search engine spiders efficiently crawl and index mobile-friendly pages on your site. This will directly impact your site’s visibility on mobile devices.
Search engine algorithms constantly evolve to provide more relevant results and an overall improved search experience for users. As these algorithms prioritize quality and user-centric content, optimizing crawl depth becomes more critical.
You need to align your crawl depth strategies in line with evolving algorithms to ensure that your important pages are effectively crawled and indexed, which will ultimately improve your search rankings and online discoverability.
FAQs About Crawl Budget Optimization
Is Crawl Budget Optimization an Important for SEO Factor?
The answer is an emphatic YES! If your website has to feature in Google search, it has to be first crawled and later indexed. If Googlebot finds thousands of new pages on your site on a single, it may skip some of the pages due to the crawl rate limit.
Crawl rate limit may end up in pages remaining as not indexed until the Googlebot crawls the website again. There is a high chance that bulk URLs (thousands to millions) added to a new website may take months to get indexed due to the Crawl rate limit allocated by Google for a specific site. This is why crawl depth optimization must be considered as an important SEO factor.
Do large websites have to worry about the crawl budget?
This depends on how popular the website is and external links pointing the site may be one of the deciding factors. If Googlebot finds high Crawl demand for the pages on a large website, it may allocate more crawl budget. However, bigger websites need to give Googlebot enough information about which pages to crawl, what all resources must be crawled, and when to crawl.
As part of the Crawl Budget Optimization, webmasters of the large websites must prioritize which pages must be crawled. Adding to this, they should ensure that the server hosting the site has enough bandwidth for the Googlebot, which may try to crawl thousands of pages within a few milliseconds. The same has been confirmed by Google’s Gary Illyes in one of his Webmaster Blog Posts. When it comes to those websites that add new pages, especially auto-generate pages based on URL parameters, these factors become all the more important.
Do small websites have to worry about the crawl budget?
Generally, smaller websites need not worry too much about the crawl budget as Google has enough crawl budget to index all the pages of a smaller website. However, smaller websites have to ensure they have good internal linking structure, hierarchy, speed, and unique pages without duplication to ensure the crawl budget doesn’t get affected. Ensuring the presence of a sitemap will lead to a higher crawl rate as it makes easier for Googlebot to find the important pages.
Google’s John Mueller in a recent webmasters hangouts session confirmed that adding the updated date of the content on the XML sitemap will help Google to crawl important and recently added pages even faster.
In addition to this, webmasters should also ensure that only the Canonical URLs are added in the sitemap as Googlebot may waste its crawl budget on trying to index duplicate pages.
Does Site Speed Negatively Affect Site’s Crawl Budget?
Another thumping YES! The slow speed of a website will negatively affect the Crawl Budget. Googlebot uses the Chrome browser to crawl and index webpages. If it finds a website slow, it can crawl only fewer number of pages. Adding to this, a website with a lot of 404 errors, and soft error pages may deter Googlebot from further crawling the site. That’s why it’s important to fix all the errors notified in Google Search Console account.
Google Search Console also offers webmasters the option to check the crawl stats of the web property. Crawl stats can help in keeping track of the fluctuations in the crawl rate and come up with quick fixes.
Making site faster with a server that has significantly less response time, means faster crawling, indexing, and a better crawl budget. Google Search Console has added a new feature to check the load speed of individual pages of a website. This can be a handy tool to ensure your site speed doesn’t affect the crawl budget.
You can also check the server logs to do an in-depth analysis of how the Googlebot treats your website. The server log files also help webmasters to see where the crawl budget is getting wasted and come up with actionable solutions.
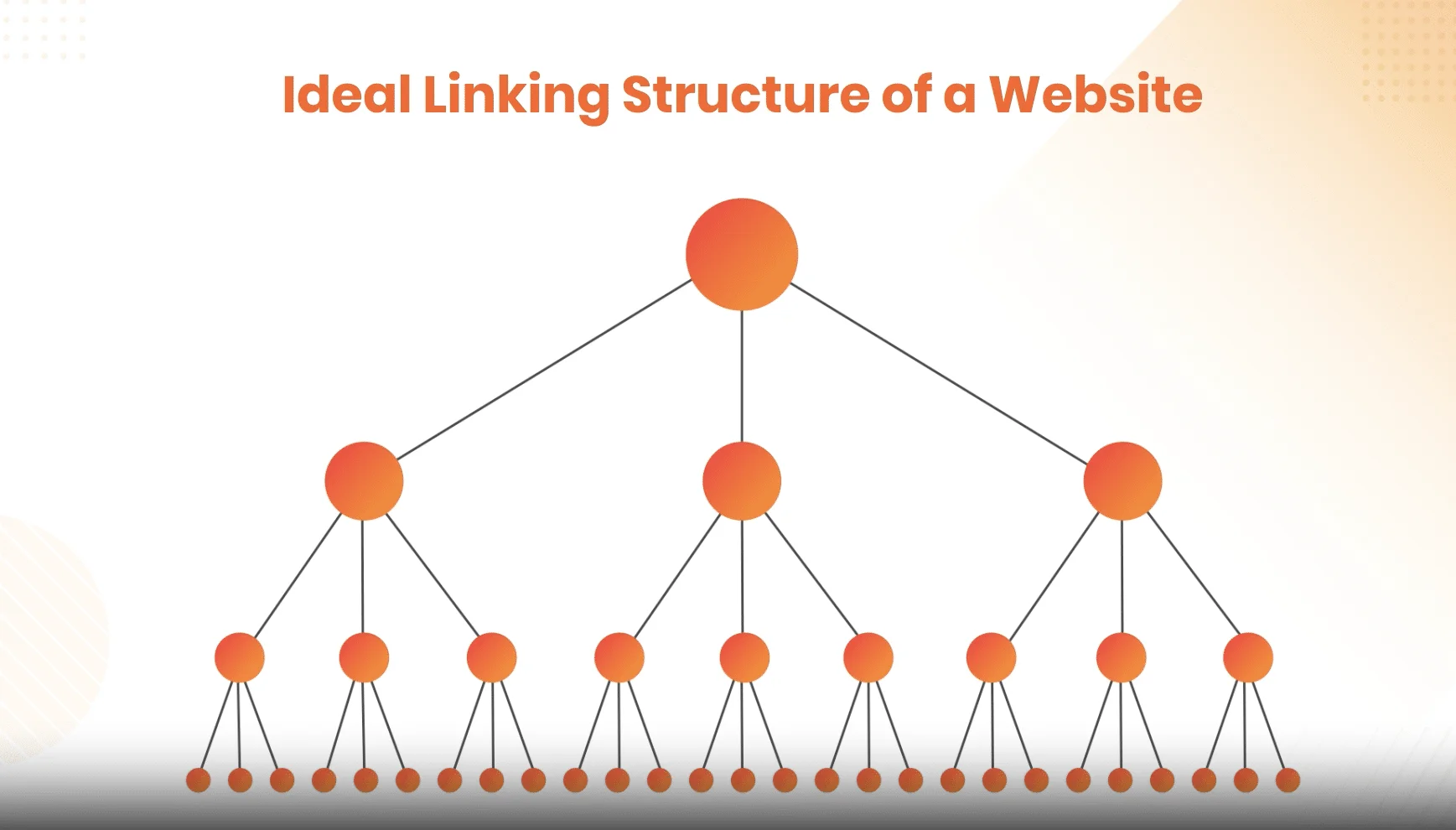
Importance of Internal Linking Structure for Crawl Budget Optimization?
Google has been quite vocal about the importance of internal linking structure and the hierarchy of the pages. A well-organized website with internal links pointing to important pages means a better crawl rate. It’s important for websites large or small to follow a pyramidical internal linking structure. This will ensure that important pages that are buried inside the website get crawled as they are linked from more important pages. An ideal internal linking structure of a website may look like:
Can orphan pages reduce the Crawl budget?
Ensuring that there are no orphan pages is a critical part of a website’s crawl budget optimization efforts. Orphan pages make it hard for Googlebot to crawl a complete website and this can lead to an abrupt rate limit stop.
Can Duplicate Content lead to a smaller crawl budget?
The crawl budget of your website will be affected by duplicate content as Google doesn’t want the same content on multiple pages to get indexed. Google has categorically stated that it doesn’t want to waste resources crawling copied pages, internal search result pages, and tag pages.
Dileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.