I assume you clicked on this link expecting a nerdy piece on robots.txt which is always considered a technical aspect of SEO and a job of the developers, right?
But don’t worry! I am primarily a content person and I acquired technical SEO skills by learning and implementing them for the last 13+ years that I have been doing SEO.
I perfectly understand how it feels for a non-technical person to learn about robots.txt and that’s why I decided to come up with this example that would make it easy for you to grasp the idea of what a robots.txt intends to do.
Imagine you’re throwing a party at your home. You’re expecting a few friends and some acquaintances who you know via social media.
At the entrance, you’ve posted a few Party Rules outlining what your guests are allowed to do and where they can go. For instance, they’re welcome to make themselves comfortable in the living room, kitchen, and backyard. However, you’ve asked them to refrain from entering your private study.
The “Party Rules” in this scenario are akin to the robots.txt file on your website, and your guests are the search engines.
The robots.txt file serves as your website’s rule book, telling search engines where they can and can’t crawl.
Like your friends who respect your privacy, most search engines will adhere to these instructions. But beware, they have the instinct to ignore these rules, similar to that one unruly party guest!
As such, the robots.txt file is a critical aspect of your website’s SEO strategy. It guides search engines to the right pages, preventing them from indexing duplicate content or accessing certain sections of your site you’d prefer to keep private.
But remember, just as you would exercise caution while drafting your “Party Rules,” be cautious when editing your robots.txt file. You wouldn’t want to accidentally block off your entire house, leaving your guests standing awkwardly at the doorstep, right?
Similarly, one wrong move in your robots.txt file can prevent search engines from accessing crucial parts of your website.
Let’s now delve deeper into the workings and implications of robots.txt.
Want to see your website at the top? Don’t let your competitors outshine you. Take the first step towards dominating search rankings and watch your business grow. Get in touch with us now and let’s make your website a star!

Definition of Robots.txt
The robots.txt is a directive that webmasters add to the root of a website to instruct the search engines which pages can be crawled and which pages cannot be. Webmasters use a set of directives that are recognized by major search engines called Robots Exclusion Protocol to control, regulate and deny search engines access to a website.
That said, robots.txt is just a directive and the access is not denied to any search engine that decides to ignore it. However, if you wish to deny access to a specific folder within your website, you can try using .htaccess. This is the safest way, as you are enforcing a rule that cannot be breached.
Importance of Robots.txt for SEO?
The whole idea behind a website deciding to invest in SEO is to rank higher on search engines. However, there can be pages and resources within the same site that the website owner wants to keep away from the eyes of the users and also the search engines. Adding a disallow directive to those folders makes them less prone to search visibility.
Another benefit of adding such directives is that you are saving the crawl budget of search engines by telling them not to crawl unnecessary pages and instead focus on just pages that you really want to rank.
Making changes to the robots.txt file has to be done with caution as one mistake can cause the whole website to become non-indexable to search engines and this will result in a ranking drop and later, the pages will disappear from the search results.
A Case Study
The case study titled “The Story of Blocking 2 High-Ranking Pages With Robots.txt“, which was recently published on the Ahrefs blog, talks about an experiment done by Patrick Stox to check if blocking pages via robots.txt had any major impact on rankings and traffic. For this he no indexed two of the high-ranking pages for a period of 5 months.
After the experiment, Patrick said that if the pages were blocked using robots.txt from being crawled, Google would still continue to rely on link relevance signals it has earned overtime to rank the content in the search result.
Key findings from the experiment include:
- The blocking resulted in a minor loss of ranking positions and all of the featured snippets for the pages. However, the overall impact was less than expected.
- The author suspects that Google may still be using the content it used to see on the page to rank it, as confirmed by Google Search Advocate John Mueller in the past.
- The test ran for nearly five months, and it didn’t seem like Google would stop ranking the page. The author suspects that after a while, Google might stop trusting that the content that was on the page is still there, but there was no evidence of that happening.
- The pages that were blocked lost their custom titles and displayed a message saying that no information was available instead of the meta description. This was expected when a page is blocked by robots.txt.
- The author believes that the message on the SERPs hurt the clicks to the pages more than the ranking drops. There was some drop in the impressions, but a larger drop in the number of clicks for the articles.
The author concludes by advising against blocking pages you want indexed, as it does have a negative impact, albeit not as severe as one might expect.
Latest Updates About Robots.txt File
Google Adds Robots.txt Report to Google Search Console
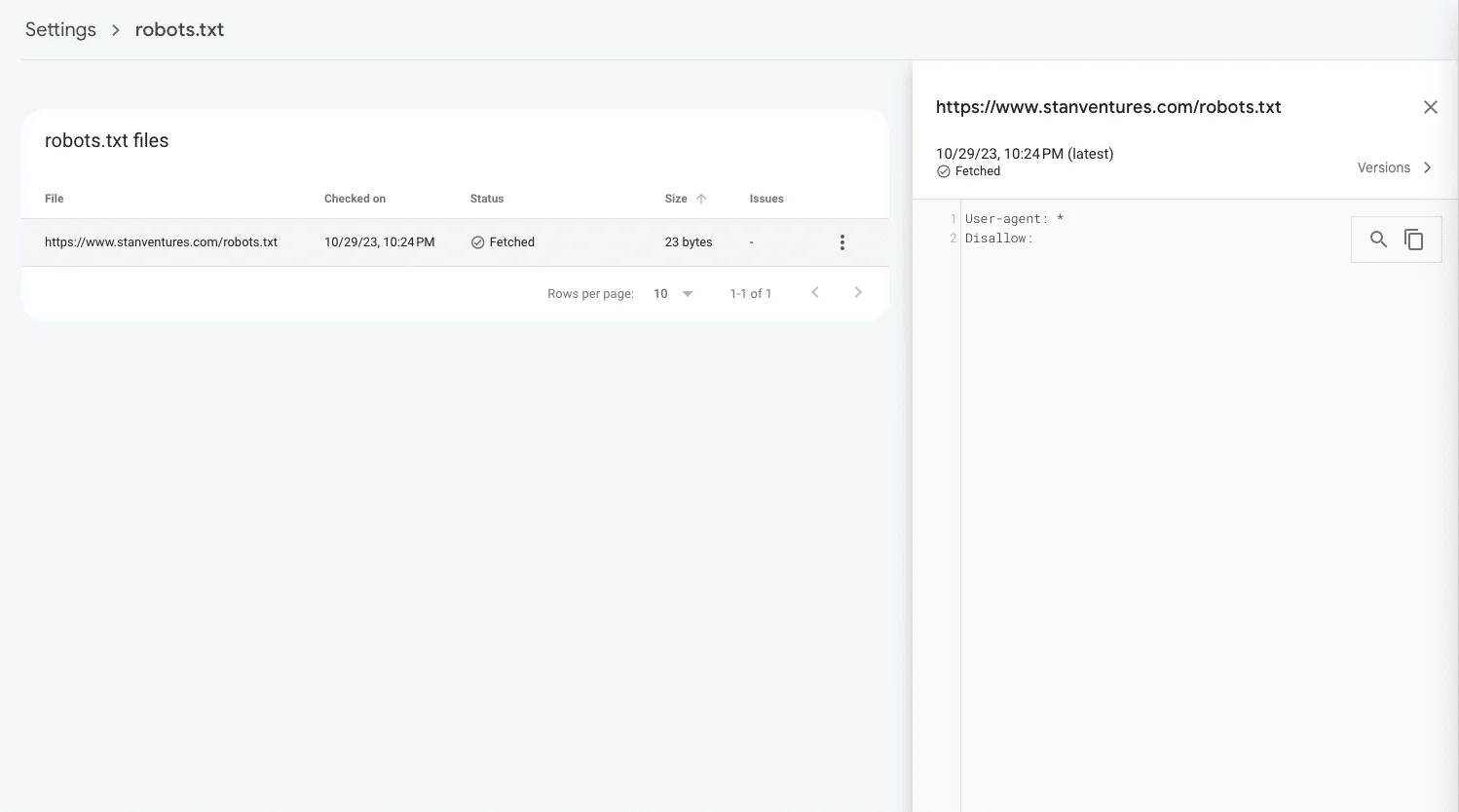
Google’s Search Console has introduced a comprehensive robots.txt report, offering webmasters a deeper insight into how Google processes their robots.txt files.
This tool is crucial for understanding and managing how search engines interact with your website.
Understanding the Robots.txt Report
The robots.txt report in Google Search Console allows you to:
- Identify which robots.txt files are discovered by Google for the top 20 hosts on your site, providing insights into how often they are crawled, along with any warnings or errors encountered.
- Understand the Fetch Status: The report categorizes the status of each robots.txt file as ‘Not Fetched’, ‘Fetched’, or ‘Not Found (404)’. This classification helps in determining whether Google can successfully access and interpret your robots.txt file.
- View the Last Fetched Version: You can examine the most recent version of a robots.txt file fetched by Google. This feature is particularly helpful in understanding the current rules Google is using to crawl your site.
- Check Previously Fetched Versions: The report allows you to see the history of fetch requests for your robots.txt file, showing changes over the last 30 days.
- Request a Recrawl: If you’ve made critical changes or fixed errors in your robots.txt file, you can request Google to recrawl it. This can be essential after unblocking important URLs or correcting significant mistakes.
When and How to Use the Robots.txt Report
- Applicability: This report is available for domain-level properties, including both Domain properties (like example.com) and URL-prefix properties without a path (like https://example.com/).
- Usage in Emergency Situations: You can request a recrawl of your robots.txt file for urgent updates, ensuring that Google is aware of critical changes as soon as possible.
- Analyzing Crawl Issues: The report is invaluable for diagnosing and fixing crawl issues that could impact your site’s visibility in search results.
Best Practices for Optimizing Robots.txt Recommended by Google
- Regular Reviews and Updates: Keep your robots.txt file updated and regularly check the report for any new errors or warnings.
- Test Before Applying: Use the report to test changes in your robots.txt file before applying them to ensure they won’t adversely affect your site’s crawlability.
- Understand the Location of Robots.txt Files: Recognize that each host and protocol combination on your site can have its own robots.txt file, and ensure they are correctly placed and accessible.
By effectively utilizing the robots.txt report in Google Search Console, you can gain better control over how Google crawls and indexes your website. This tool is an essential part of modern SEO strategies, helping you to ensure that your site is accurately represented in search engine results.
Google Stops Support to Old Robots.txt Testing Tool
Google has confirmed that the old robots.txt testing tool will no longer be functional after December 23rd and is advising webmasters to use the new robots.txt report instead.
Google Planning for Robots.txt Alternatives
Google is now planning to explore alternatives to robots.txt, the 30-year standard protocol in order to better control crawling and indexing in the wake of generative AI and other advanced machine-learning technologies.
In fact, Google states,” We believe it’s time for the web and AI communities to explore additional machine-readable means for web publisher choice and control for emerging AI and research use cases.”
The search engine giant will invite people from the web and AI communities, including web publishers, civil society, academia and many others across the world, for a public discussion regarding the same. This discussion is expected to happen in the coming months.
Google has been quite obsessed with AI for some time now. At Google I/O 2023, they did highlight their commitment to developing helpful AI products and features.
So, what precisely triggers the need for a robots.txt alternative amid the surge of AI in search?
Open AI has recently disabled the browse with Bing feature in ChatGPT (which was available only for ChatGPT Plus members) after it was found that AI Chatbot was able to access paywalled content without the consent of the publisher.
After all, one of the advantages of adding the robots.txt directive is to tell the search engine not to crawl a particular page.
Now the shock waves initiated by this issue while AI-driven search is booming as an inevitable is probably one of the reasons why Google set itself up to come up with an alternative for robots.txt.
Webmasters are very much used to leveraging robots.txt to extend some control over the search engine bot’s access to their content. But then, in the light of recent events and with Google looking for an alternative, we can expect new methods and protocols to arrive in the near future.
Where to Can SEOs Find Robots.txt File
The robots.txt file is typically found in the root directory of your website. To access it, you would either need a plugin like Yoast or FTP access to your server.
Here is how you can find the robots.txt file using FTP:
- Start by accessing your website’s root directory. This is the main folder that contains all the files and directories for your website.
- In most cases, you can access the root directory through FTP (File Transfer Protocol) using an FTP client such as FileZilla or through your web hosting control panel.
- Once you have accessed the root directory, look for a file named “robots.txt”. This is where the robots.txt file is typically located. If you don’t see the file, it means that one hasn’t been created for your website yet.
- If you can’t find the robots.txt file, you have the option to create one. Simply create a new text file and name it “robots.txt”. Make sure to place it in the root directory of your website.
- After locating or creating the robots.txt file, you can edit it using a text editor such as Notepad or any other plain text editor.
Note: There are chances that you may not find robots.txt file in the root directory. That means it doesn’t exist. But don’t worry, you can create a robots.txt file using the protocols mentioned in the article and upload it to the root directory. It will work perfectly. However, make sure you are uploading a .txt file and not a text editor version like .doc or .page.
If you are not a technical person, you may choose to install Yoast SEO Plugin. Once installed, you can edit the robots.txt file using this plugin.
Here is how you do it using the Yoast SEO Plugin
- Log in to your WordPress dashboard.
- Navigate to the “SEO” section in the left-hand menu and click on “Tools” within the Yoast SEO menu.
- In the “Tools” tab, click on the “File Editor” option.
- You will be presented with a screen displaying the robots.txt file content. If the file doesn’t exist yet, you can create one by clicking on the “Create robots.txt file” button.
- The Yoast SEO plugin provides a user-friendly interface where you can edit the robots.txt file. Make the necessary changes or additions as required.
- Once you have made the desired modifications, click on the “Save changes to robots.txt” button to save your changes.
Elements inside a Robots.txt File
The robots.txt file is made up of directives that guide how search engine robots should interact with the site. Here are some of the key components you’ll find inside a typical robots.txt file:
User-agent:
The element User-agent is used to specify web crawlers that the rule applies to. This is the first rule set that should appear inside a robots.txt file.
If you want to apply the same set of rules to all web crawlers, you will use an asterisk (*).
Example: User-agent: *
If you want to specify a user agent, then provide the name of that.
Example: User-agent: Googlebot
Here’s a list of the user-agents you can use in your robots.txt file to match the most commonly used search engines:
| Search engine | Field | User-agent |
| Baidu | General | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot | |
| Images | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | General | slurp |
| Yandex | General | yandex |
If you want to know more about Google’s user agents and query strings, check out this article.
Disallow:
This second directive that you can find in a robots.txt file. It is used to tell a search engine crawler which pages must be excluded from crawling.
When you use the Disallow directive with a forward slash (/), it’s a wildcard directive for the user agent that you have selected to not to scan any of your pages.
Example: Disallow: /
If you want one or more specific folders to be ignored, you can use the disallow directive along with the subfolder or the URL path.
Example: Disallow: /private/
Allow:
When the original Robots Exclusion Protocol, also known as the Robots Exclusion Standard or robots.txt protocol, was released in 1998, it didn’t include the Allow directive.
However, the “Allow” directive, which indicates URLs and folders that can be crawled because of the robots.txt protocol after Google and other search engines started using it.
When you use the Allow directive with a forward slash (/), it’s a directive for the user agent that can crawl all the pages on the site without restrictions.
Example: Allow: /
If you intend to allow only a specific URL/subfolder within a disallowed page, you can define the page explicitly in the detective.
Example:
Disallow: /private/ Allow: /private/public_file.html
Sitemap:
This is, again, a search engine-specific directive that helps the crawlers to identify the sitemap URL of the website. Adding the sitemap of your website in the robots.txt file will help search engines easily navigate to the sitemap file that houses important URLs of your website.
Example: Sitemap: http://www.example.com/sitemap.xml
Crawl-delay:
This is one of the directives that Google nowadays doesn’t honor. This directive is intended to control the crawler from using a huge bandwidth of the website through successive crawl attempts.
While most search engines don’t honor this directive, a few, like Bing and Yandex still do.
Example: Crawl-delay: 10,min mjhm,mm nmj ≥
Don’t block CSS and JS files in robots.txt
SEO is an industry where today’s rules can become taboos of the future. In fact, SEOs thought blocking the CSS and JS from robots.txt was the best way to optimize the crawl budget. But this myth was busted by Google in 2015 when they announced that blocking JavaScript and CSS against its guidelines will lead to ranking drops.
Blocking CSS and JavaScript made it difficult for Google to understand exactly how users interact with a web page. When more emphasis was given to the user experience, Google found that a lot of websites were blocking their CSS and JavaScript. This made it difficult for search engine algorithms to emulate the real user experience.
Here’s the rub. When you block CSS and JavaScript files using robots.txt, Google’s robots, in fact, fail to understand whether your website is loading correctly. What this did essentially was put a blindfold on the Google Algorithms, not allowing Google’s bots to see your website as it’s meant to be seen by the users.
Consider this example. You are running an online store and use JavaScript to display product reviews left by your customers. If you have blocked Googlebot from crawling your JavaScript, that means it cannot read the reviews, which can hamper your ranking potential.
You don’t have to write an explicit directive to allow CSS and javascript. All you need to do is that you are not disabling it by adding a code like:
User-agent: * Disallow: /scripts/ Disallow: /styles/
8 Common Robots.txt Mistakes and Fixes
1. Robots.txt Not In The Root Directory
- Mistake: The robots.txt file is incorrectly placed in a subdirectory (e.g.,
www.example.com/folder/robots.txt) instead of the root directory. This mistake prevents search engine bots from discovering and following the directives laid out in the file. - Impact: Search engines will act as if the website does not have a robots.txt file, potentially leading to uncontrolled crawling of the site.
- Fix: Ensure the robots.txt file is placed in the root directory (
www.example.com/robots.txt). This ensures that it’s the first thing search engine crawlers find and adhere to when accessing your site.
Example Mistake: URL of the misplaced robots.txt file: https://www.example.com/subfolder/robots.txt
2. Poor Use Of Wildcards
- Mistake: Overuse or incorrect application of wildcards in the robots.txt file, such as
User-agent: * Disallow: /*.jpg$, can inadvertently block or allow too much access. - Impact: This can lead to essential content being blocked from search engines or private content being accidentally indexed.
- Fix: Use wildcards judiciously and verify their behavior with a robots.txt tester. Precise, minimal use ensures only the intended parts of the site are blocked or allowed.
Example Mistake:
User-agent: *
Disallow: /*?
This inadvertently blocks all URLs containing a question mark, potentially blocking dynamic pages that should be indexed.
3. Noindex In Robots.txt
- Mistake: Including a
noindexdirective in robots.txt (e.g.,Disallow: /page.html Noindex: /page.html) is outdated and no longer supported by Google since September 2019. - Impact: Pages you intended to keep off search engine results pages (SERPs) might still get indexed.
- Fix: Remove
noindexdirectives from robots.txt and use anoindexmeta tag within the HTML of the pages you wish to exclude from indexing.
Example of the Mistake:
User-agent: *
Disallow: /private/
Noindex: /private/
4. Blocked Scripts And Stylesheets
- Mistake: Using
Disallow: /js/orDisallow: /css/in robots.txt blocks search engines from accessing critical JavaScript or CSS files needed for rendering pages correctly. - Impact: Blocking these resources can prevent search engines from accurately rendering and understanding your site, potentially harming your site’s visibility in SERPs.
- Fix: Remove disallow directives for CSS and JS files to ensure search engines can fully render your site.
Example of the Mistake:
User-agent: *
Disallow: /css/
Disallow: /js/
5. No Sitemap URL
- Mistake: Failing to include the sitemap URL in robots.txt (e.g., omitting
Sitemap: http://www.example.com/sitemap.xml) misses an opportunity to guide search engines more effectively through your site. - Impact: Without a sitemap directive, crawlers may not discover all of your site’s content, potentially impacting your site’s indexing.
- Fix: Add the
Sitemap:directive followed by the full URL of your sitemap to help search engines crawl your site more comprehensively.
Example Mistake:
User-agent: *
Disallow: /tmp/
Disallow: /private/
Allow: /6. Access To Development Sites
- Mistake: Not using
Disallow: /in the robots.txt file of a development site allows search engines to index content that’s not ready for public viewing. - Impact: Development content appearing in search results can confuse users and dilute your site’s SEO efforts.
- Fix: Use a
Disallow: /directive in the robots.txt of development sites to prevent any indexing. Remember to remove this directive when the site goes live.
Example Mistake:
User-agent: *
Allow: /7. Using Absolute URLs
- Mistake: Specifying disallow rules with absolute URLs (e.g.,
Disallow: http://www.example.com/private/) instead of using relative paths from the root. - Impact: Misinterpretation by crawlers, as robots.txt only recognizes relative paths, potentially leading to incorrect crawling behavior.
- Fix: Always specify paths relative to the root in the robots.txt file to ensure the rules are correctly interpreted and followed by crawlers.
Example Mistake:
User-agent: *
Disallow: http://www.example.com/private/
8. Deprecated & Unsupported Elements
- Mistake: Including unsupported or deprecated directives like
Crawl-delay:orNoindex:in robots.txt. - Impact: These elements will be ignored by Google, leading to potential mismanagement of how your site is crawled and indexed.
- Fix: Remove deprecated elements from your robots.txt. Use supported methods, such as configuring crawl rate in Google Search Console and using
noindexmeta tags for pages you don’t want indexed.
User-agent: *
Crawl-delay: 10
Noindex: /private/
Navigating the world of robots.txt can be less daunting than it appears, even for those new to technical SEO. As we’ve explored, this powerful tool is much like setting ground rules at a party: it guides search engines to the areas of your website you want to showcase and keeps private spaces hidden. Remember, the robots.txt file is not just a set of directives; it’s an integral part of your SEO strategy, helping you manage search engine access and conserve crawl budget effectively.
However, as with any powerful tool, caution is key. Incorrect configurations can lead to unintended SEO consequences, such as making your entire site invisible to search engines. Always test changes carefully and consider consulting with an SEO professional if you’re unsure.
As the digital landscape continues to evolve, especially with the emergence of AI and new search technologies, staying informed and adaptable is crucial. Embrace the robots.txt file as a dynamic ally in your SEO journey, and you’ll be well on your way to achieving a well-indexed, visible, and successful website.”
This conclusion aims to reinforce the key messages of your blog, while also encouraging the reader to view robots.txt as a valuable and manageable component of their SEO strategy.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.



