Google has quietly uploaded an LLMs.txt file to the Google Search Central developer documentation portal, despite repeatedly telling SEOs and publishers that the file is not used, not needed, and should ideally be noindexed.
The file, located at developers.google.com/search/docs/llms.txt, was spotted by SEO expert Lidia Infante, triggering a flood of reactions across the search community.
And yes, we had covered this a few months back, when Google very clearly stated the total opposite: that LLMs.txt is unnecessary, unsupported, and irrelevant to Google Search or AI crawling behavior.
So… what exactly is happening now?
Why Is Google Uploading a File It Previously Said Was Useless?
As per our latest coverages and even for months, Google’s stance was firm:
- Google does not use LLMs.txt
- Nobody uses it
- It’s probably a waste of time for webmasters
- If someone still wants to host it, Google suggested noindexing it
Those statements were made publicly by Google representatives, including Search team members.
Which is why the SEO community collectively raised an eyebrow when Google itself uploaded the very file it dismissed.
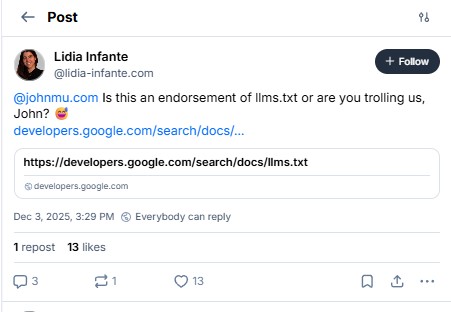
The discovery spread quickly when Lidia Infante posted a screenshot on Bluesky, tagging Google’s John Mueller and asking: “Is this an endorsement of LLMs.txt or are you trolling us, John?”
John’s reply? “hmmn :-/”
A cryptic reaction that only deepened the confusion.
This moment perfectly captures the ongoing tension between what Google says about emerging AI-related protocols and what it actually does internally.
How Did the SEO Community React to Google’s Sudden Shift?
Let’s see what unfolded. The reaction across Bluesky and SEO forums was a mix of humor, suspicion, and frustration. After all, Google had been:
- Downplaying the purpose of LLMs.txt,
- Discouraging its use
- Criticizing the idea that AI crawlers need a separate governance protocol.
Yet here they are… using one.
Some SEOs called it “classic Google irony.” Others wondered if this signals a future integration of LLM-specific crawling controls, similar to how robots.txt began as a voluntary convention before becoming foundational for search engines.
A few simply called it trolling. But the underlying sentiment was clear:
“If Google doesn’t use it, why did Google use it?” A fair question.
Does Google’s LLMs.txt File Mean Google Is Adopting the Standard?
According to Bluesky’s discussion, here are some of the possibilities.
Possibility 1: Google is quietly testing future functionality
It wouldn’t be the first time Google denied early-stage experiments to avoid speculation. LLMs.txt has gained momentum in the AI ecosystem, especially with LLMs, AI agents, and crawlers proliferating faster than existing protocols can govern.
Even if Google Search doesn’t use it today, Google’s internal AI teams (Gemini, indexing, AI Overviews, dataset crawlers, etc.) might be preparing for a shared industry standard.
Possibility 2: The upload is accidental or a developer-level experiment
Given the minimalist content inside the file, some believe a Google engineer may have uploaded it for testing or internal documentation purposes.
Possibility 3: Yes, it’s trolling
John Mueller’s emoji-laden “hmmn :-/” certainly didn’t help calm anyone’s curiosity.
But would Google really troll the SEO industry through its own Search Central site?
(Then again, this is the same industry that’s been debating the spacing of meta descriptions for 20 years…)
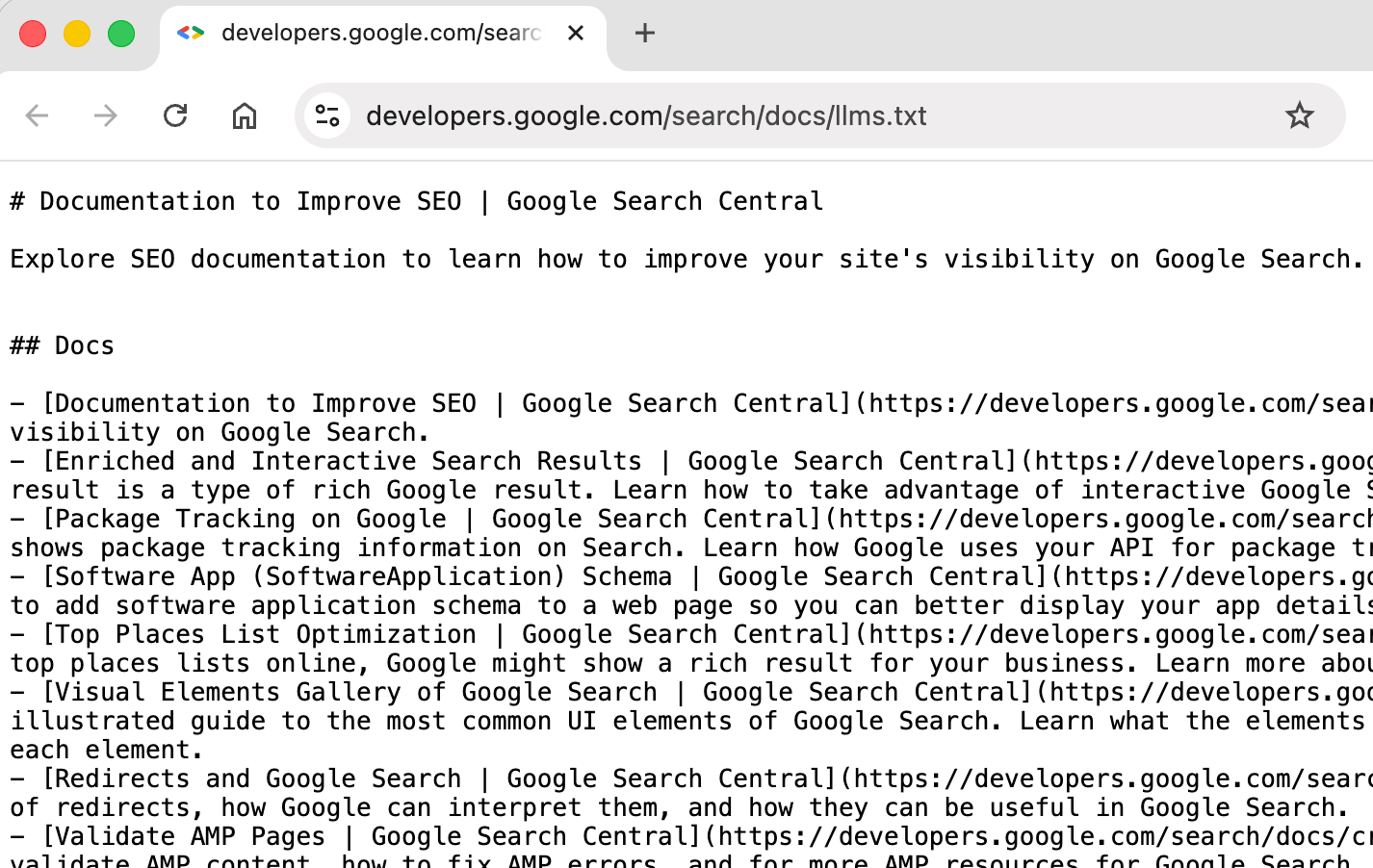
What Exactly Is Inside Google’s LLMs.txt File?
The file’s contents are simple and almost suspiciously so. It includes:
- A reference to Google Search developer documentation
- Basic metadata
- Nothing that defines permissions or blocks
This is what made SEOs even more curious. The file isn’t being used to block or allow anything. It looks more like a placeholder, a marker, or even a signal that Google is experimenting with the convention.
If Google simply wanted to prove “nobody uses this,” posting one of their own seems contradictory.
Is This a Reversal of Google’s Earlier Messages?
This is where the story gets interesting. Yes. It directly contradicts Google’s previous guidance.
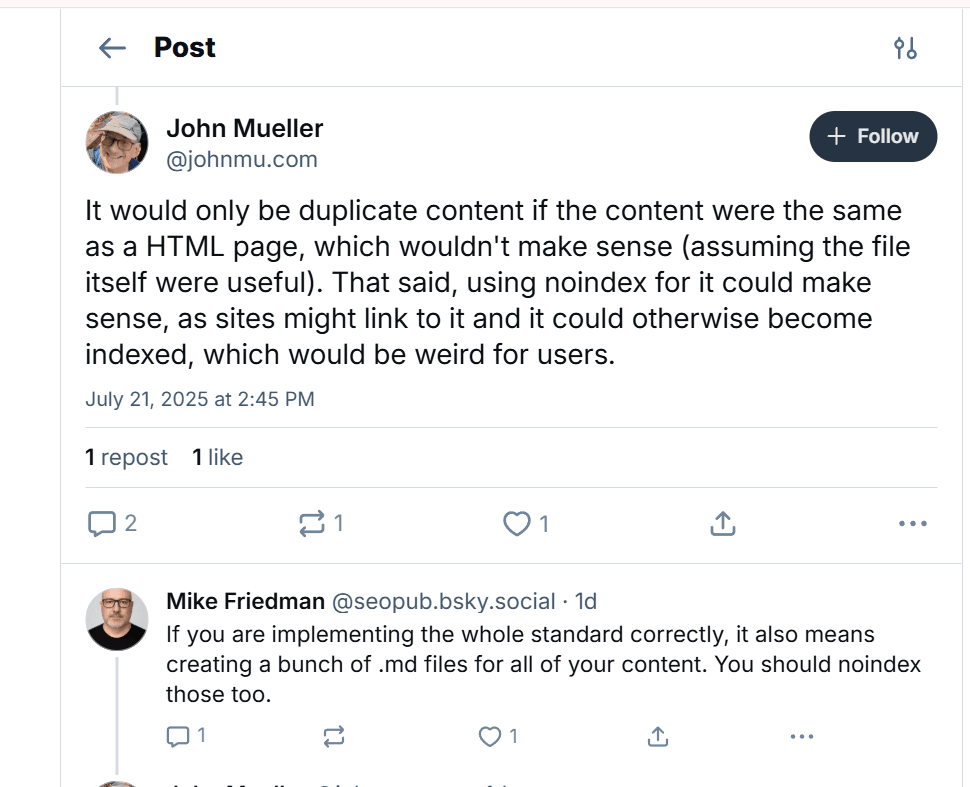
A few months ago, we covered Google’s statements where they clearly communicated:
- They do not work with LLMs.txt
- They do not crawl based on it
- They see no value in publishers using it
- They recommend noindexing the file to avoid clutter
Now? They have published one. When a company of Google’s scale makes such a move, even unintentionally, the SEO world pays attention.
This isn’t the first time Google has contradicted itself in execution versus communication, structured data rollouts, indexing pipeline updates, supplemental crawl protocols, and AI Overviews all carried similar patterns.
But this contradiction is especially notable because it happens at a time when the world is asking: “How should websites handle AI crawlers?”
Google’s confusing stance only magnifies that uncertainty.
Is Google Preparing for a Future AI Crawling Protocol?
Reason 1: LLM crawling is exploding
AI companies scrape data at unprecedented scale. Websites want a way to control, allow, or monetize AI training usage.
Reason 2: Robots.txt is outdated for AI models
Robots.txt was created in 1994, long before LLMs, embeddings, retrieval pipelines, or machine training existed.
A new protocol like LLMs.txt could:
- Define AI training permissions
- Help publishers opt in/out of dataset collection
- Create transparency for crawlers
- Enable attribution
- Reduce legal risk
Google may be preparing for industry alignment, even if it’s not ready to publicly admit it.
Reason 3: Google wants to maintain leadership in standards
If third-party AI companies adopt LLMs.txt widely, Google can’t ignore it forever.
Uploading this file might be an early step toward participating in the broader AI governance ecosystem.
What Should Website Owners Do Now?
- Do not rush to implement LLMs.txt, Google still maintains it doesn’t use it.
- Monitor industry adoption, especially by AI crawlers outside Google (OpenAI, Anthropic, Perplexity, etc.).
- Keep robots.txt updated, as it remains the only officially recognized crawling control.
- Track Google’s statements, any shift in tone could indicate future support for AI-specific crawl governance.
- Document AI crawler activity on your logs to understand how models are accessing your site.
- Stay flexible, LLMs.txt may evolve into a meaningful standard, but it is not one today.
Key Takeaways
- Google uploaded an LLMs.txt file despite previously saying it’s useless.
- This directly contradicts Google’s earlier statements advising webmasters not to use the file.
- The move may indicate internal testing, future protocol exploration, or simply playful trolling.
- Google has not announced any official support or functionality tied to LLMs.txt.
- The SEO community is treating it as a potential signal of evolving AI crawling standards.

Dipti Arora
AuthorDipti Arora is a Senior Content Writer with over seven years of experience creating impactful content across Digital Marketing, SEO, technology, and business domains. She has a strong background in managing news verticals and delivering editorial excellence. Dipti has contributed to leading publications such as The Times of India and CEO News, where her research-driven storytelling and ability to simplify complex subjects have consistently stood out. She is passionate about crafting content that informs, engages, and drives meaningful results.