A new benchmark shows that advanced language models, including newer GPT versions, continue to produce incorrect answers at a noticeable rate, raising ongoing concerns for businesses that rely on AI for factual analysis and decision-making.
The study examined how well large language models handle a basic but critical task. Can they accurately pull facts from a given document without adding information that is not there?
Researchers tested 37 models using 60 questions based on CNN News articles. Each question required a precise answer drawn directly from the text. If the article did not include the information, the correct response was “not given.” Any attempt by a model to guess or infer missing details is counted as a hallucination.
This setup closely mirrors how companies use AI in real workflows. From summarizing reports to answering questions from internal documents, businesses expect systems to stick to the source material. In these cases, guessing can be more damaging than saying nothing at all.
What the Results Show About Modern AI
The results show that hallucinations are still common. Even top-performing models reported hallucination rates of more than 15% when asked to analyze supplied content.
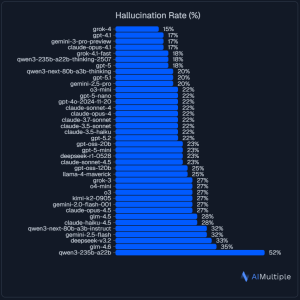
Some models performed better than others, but no system eliminated the issue entirely.
One surprising insight was the lack of a clear link between accuracy and context window size. Models designed to handle extremely large inputs did not consistently outperform those with smaller limits. Reliable and unreliable models appeared across both categories.
Cost also failed to predict accuracy. When prices were normalized to reflect typical usage, there was no simple pattern showing that more expensive models hallucinate less. Architecture quality and training choices mattered more than raw specifications.
How Accuracy Was Checked
To avoid unfair scoring, the evaluation used multiple layers of verification. Answers were first checked for an exact match against the source. If that failed, a semantic check looked for equivalent meanings written in different ways.
A final review step examined unclear cases, with manual checks added when needed.
Only answers that failed every stage were labeled as hallucinations. This approach reduced false positives and strengthened confidence in the results.
Why Hallucinations Still Happen
Several underlying issues continue to drive the problem.
Training data gaps are a major factor. When models lack strong coverage in a topic, they often generate plausible but false details instead of admitting uncertainty. Outdated or biased data can also lead to errors.
The way language models generate text adds another layer of risk. They are built to produce fluent responses, not to verify facts. As a result, a confident tone can mask inaccuracies.
Prompt design also plays a role. Vague instructions give models more freedom to stray beyond the source material. Clear prompts help, but they do not eliminate the risk.
Why This Is a Business Issue, Not a Research Detail
Hallucinations carry real consequences. Inaccurate outputs can damage trust with customers, expose organizations to legal risk, and slow down workflows when humans must double-check everything.
In regulated sectors such as healthcare, finance, and law, a single false statement can trigger compliance problems. Even in less regulated environments, repeated errors reduce confidence in AI tools and limit adoption.
How AI Accuracy Issues Are Changing Search
The accuracy problem does not stop with chatbots and internal tools. Search engines are also leaning more heavily on language models to interpret pages, summarize information, and decide which sources appear in AI-generated results. These systems are expected to understand content quickly and represent it correctly, often without human review.
When facts are unclear, loosely written, or inconsistently presented, AI systems are more likely to misinterpret what a page is saying or avoid using it altogether. This mirrors the same behavior seen in hallucination benchmarks, where models struggle most when they are forced to infer missing details rather than extract clear information.
As a result, content is no longer evaluated only by keywords or links. It is increasingly assessed by how clearly it communicates meaning, context, and factual relationships to automated systems. Pages that define entities, state facts directly, and maintain consistent signals are easier for AI-driven search systems to process and trust.
This shift has given rise to AI SEO, which focuses on aligning content structure and clarity with how modern search systems interpret information. Rather than chasing new ranking tricks, the goal is to reduce ambiguity so AI systems can retrieve, summarize, and surface content accurately.
What Actually Helps Reduce Errors
There is no single fix, but some approaches consistently improve reliability.
Retrieval-augmented generation (RAG) helps ground responses in verified sources, such as internal documents or curated databases. When retrieval quality is monitored, hallucinations tend to drop.
System design matters as much as prompt wording. Models should be told clearly when to answer and when to say they do not know. Cross-checks, tool-based validation, and secondary reviews add important safeguards.
Some organizations are also exploring agent-style systems that retrieve information, compare sources, and revise answers before presenting a final response. These extra steps make mistakes easier to catch.
Practical Guidance for Teams Using AI
Teams should assume hallucinations will happen and design around that reality.
Model selection should be based on testing with real, domain-specific tasks rather than marketing claims. High-impact outputs should pass through verification layers before being shared or published.
AI works best as a support tool, not a final authority, especially when accuracy matters.
Why Bigger Models Are Not a Safety Net
One of the most important lessons from the benchmark is that scale alone does not guarantee trust. Large context windows and higher costs do not ensure factual consistency.
What matters more is how the model is trained, how it is connected to reliable data, and what checks surround its output. Without those elements, even advanced systems can fail in predictable ways.
Key Takeaways
- Advanced AI models still hallucinate at meaningful rates.
- Large context limits do not ensure better accuracy.
- Price and brand name are weak signals of reliability.
- Grounding responses in verified sources reduces errors.
- Verification and system design are critical for safe use.

Zulekha
AuthorZulekha is an emerging leader in the content marketing industry from India. She began her career in 2019 as a freelancer and, with over five years of experience, has made a significant impact in content writing. Recognized for her innovative approaches, deep knowledge of SEO, and exceptional storytelling skills, she continues to set new standards in the field. Her keen interest in news and current events, which started during an internship with The New Indian Express, further enriches her content. As an author and continuous learner, she has transformed numerous websites and digital marketing companies with customized content writing and marketing strategies.