A new study shows that popular AI tools almost never agree on brand or product recommendations, exposing major flaws in the fast-growing business of AI visibility and ranking analytics.
Research published by marketing strategist Rand Fishkin finds that leading AI systems such as ChatGPT, Claude, and Google’s AI Overviews produce highly inconsistent brand and product recommendations.
Based on thousands of repeated AI responses across consumer and business categories, the study concludes that ranking brands inside AI answers has little meaning, while limited forms of visibility measurement may still offer cautious insight
Why This Question Matters
Over the past few years, companies have rushed to understand how their brands appear inside AI answers. That rush has turned into real money. Industry estimates suggest that more than $100 million a year is already being spent on tools that claim to track AI rankings and brand presence.
What was missing until now was a simple reality check. Do AI systems behave consistently enough to justify those metrics? Fishkin’s research set out to test that assumption directly, after finding no public studies that answered the question.
How the Research Was Done
The study relied on more than 600 volunteers who repeatedly ran the same prompts across three major AI platforms.
In total, 2,961 responses were collected from 12 prompts covering a wide range of topics, from chef’s knives and headphones to cloud computing providers, marketing agencies, and cancer care hospitals.
Participants copied AI responses exactly as they appeared. The data was then cleaned and analyzed to identify how often brands appeared, how frequently lists repeated, and whether ordering showed any stability.
The methodology drew inspiration from established academic work on large language model consistency.
What the Data Showed
The most striking finding was how rarely AI tools repeated themselves.
In fewer than one out of 100 cases did an AI return the same list of brands twice for the same question. Seeing the same list in the same order was even less common, occurring in fewer than one out of 1,000 runs.
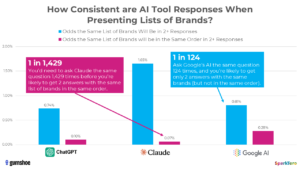
The variation went beyond order. AI systems changed the length of their lists, sometimes offering just a handful of options and other times more than ten. They also differed in which brands appeared at all, occasionally recommending inactive businesses or outdated products.
These patterns held true across all three AI platforms tested. The conclusion was hard to ignore. AI recommendation lists are inherently unstable.
Why Rankings Fall Apart
Because the order of recommendations changes so dramatically, the research finds that ranking position inside AI answers is effectively meaningless.
A brand might appear first in one response, fourth in the next, and disappear entirely in another, all without any change in the prompt.
This instability creates a risk for misuse. A tool or consultant could rerun prompts repeatedly until a favorable result appears, then present that snapshot as evidence of success.
The findings challenge emerging AI SEO strategies that attempt to optimize brand performance based on ranking position inside AI-generated answers.
Where There Is Still Signal
Despite the disorder, the research uncovered one pattern that held more consistently. While rankings shifted, certain brands appeared again and again across many runs of the same prompt. Measuring how often a brand shows up, expressed as a visibility percentage, proved far more stable than tracking position.
In categories with limited options, such as regional healthcare providers or cloud services, top brands appeared in most responses, sometimes more than 90% of the time. In larger, more crowded spaces, visibility rates dropped into the 30% to 40% range, reflecting the broader pool of possible answers.
The research shows that brand mention frequency across repeated AI responses provides a more reliable indicator than ranking order.
The Overlooked Issue of Prompts
One of the most revealing parts of the study focused on how people actually ask AI questions.
When volunteers were asked to write their own prompts for the same task, almost none of them looked alike. Semantic similarity between prompts was extremely low, even when everyone was trying to accomplish the same goal.
This matters because many AI tracking tools rely on a small set of standardized or synthetic prompts.
The research shows that real-world AI usage is far more varied, personal, and unpredictable. Any system that ignores this diversity risks producing misleading results.
Human Prompts Still Lead to Familiar Brands
To test whether prompt diversity makes tracking impossible, the study compared AI responses from human-written prompts with those generated from synthetic prompt sets.
The outcome was unexpected. Even with wildly different wording, AI systems often returned a familiar group of brands when the underlying intent was the same.
For example, hundreds of unique prompts about buying headphones still surfaced the same major manufacturers in more than half of all responses.
This indicates that AI models often capture intent beneath the surface language, supporting the idea that visibility percentage can still reflect something real when measured carefully.
Implications Beyond Marketing
The findings raise concerns about trust in AI recommendations. Many users assume that AI lists are ordered by quality or expertise. The research shows that this assumption is unfounded.
In sensitive areas such as healthcare, this misunderstanding could have serious consequences.
A hospital or service may appear frequently but rarely at the top of a list, with no clear explanation. The order itself carries no reliable meaning.
Fishkin argues that AI tools should clearly disclose that recommendation lists are randomized outputs rather than endorsements or expert judgments.
What Marketers and Leaders Should Do
Organizations considering AI visibility tools should approach them with caution. Ranking position should be disregarded entirely. Any attempt to measure AI presence should rely on large numbers of prompts, repeated runs, and transparent statistical methods.
Vendors should be able to explain how their data is collected, how many runs are required for confidence, and how closely their prompts reflect real user behavior. Without that transparency, AI visibility metrics risk becoming expensive guesswork.
Key Takeaways
- Research by Rand Fishkin shows AI tools rarely repeat the same brand recommendations.
- The study finds the ranking order in AI answers changes too frequently to be reliable.
- Repeated brand appearances offer a more stable signal than ranking position.
- Highly varied user prompts limit the precision of AI visibility tracking.
- Transparent methodology is critical for any AI tracking measurement to hold value.

Zulekha
AuthorZulekha is an emerging leader in the content marketing industry from India. She began her career in 2019 as a freelancer and, with over five years of experience, has made a significant impact in content writing. Recognized for her innovative approaches, deep knowledge of SEO, and exceptional storytelling skills, she continues to set new standards in the field. Her keen interest in news and current events, which started during an internship with The New Indian Express, further enriches her content. As an author and continuous learner, she has transformed numerous websites and digital marketing companies with customized content writing and marketing strategies.