A wave of major websites, including prominent names like The New York Times, Amazon, and Wired, have decided to block OpenAI’s GPTBot, citing privacy concerns and the potential misuse of their content, says a report published by Originality.ai.
This move follows OpenAI’s recent launch of SearchGPT and OAI-SearchBot in July 2024, sparking widespread debate about the ethics and future of AI in content creation and consumption.
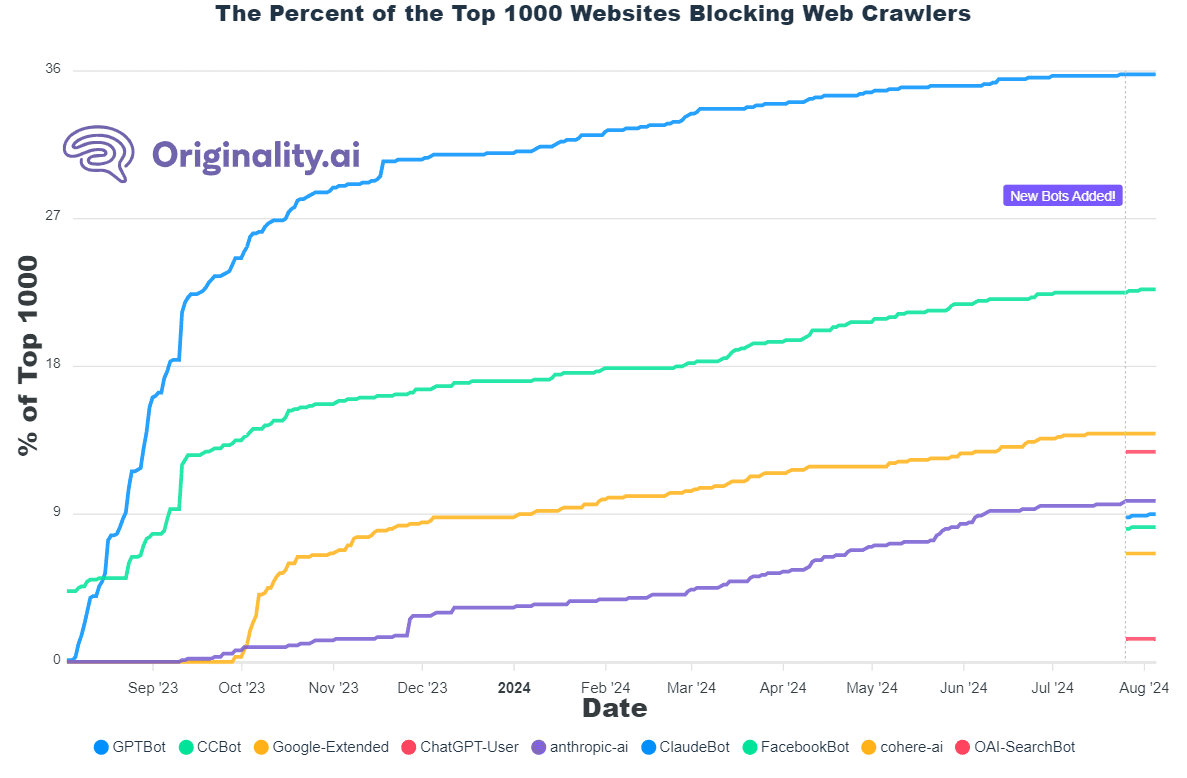
Rising Tensions with AI Content Crawlers
The study published in August 2024 revealed that 26.15% of the top 1000 websites globally have now blocked GPTBot. This increase in resistance comes despite OpenAI’s assurances that these bots are not intended for training AI models but rather for linking and surfacing websites in search results.
Key Findings from the Latest Research
Blockage of GPTBot: 25.9% of top websites, including high-profile names like The New York Times and Vogue, have blocked GPTBot.
Resistance to OAI-SearchBot: 14 leading publishers, wary of potential content misuse, have blocked OAI-SearchBot despite OpenAI’s clarifications.
New Entrants: Platforms like Reddit, Pinterest, Amazon, Quora, and Indeed have joined the list of sites blocking GPTBot, highlighting a growing trend among content providers to safeguard their data.
Historical Context and Initial Reactions
OpenAI launched GPTBot on August 7, 2023, intending to enhance its AI capabilities by crawling the web for publicly available data. This launch was met with immediate scrutiny from major websites concerned about privacy and content appropriation.
First Major Blockage
The very next day, August 8, 2023, Reuters.com became the first “Top 100” website to block GPTBot. This move set a precedent, signaling to other content providers the potential risks of allowing unrestricted AI access to their data.
Initial Resistance
Within the first two weeks following the launch, six major websites took decisive action to block GPTBot, reflecting widespread unease about OpenAI’s new crawler. These early blockers included:
- Amazon.com – Blocked GPTBot on August 17, 2023, underscoring concerns about protecting proprietary content.
- Quora.com – By August 22, 2023, Quora had implemented measures to block GPTBot, likely due to fears of content being repurposed without consent.
- NYTimes.com – The New York Times, a leader in digital journalism, blocked the bot on August 17, 2023, aiming to safeguard its premium content.
- Shutterstock.com – On August 21, 2023, Shutterstock, a major provider of stock images, blocked GPTBot to prevent its extensive image library from being scraped.
- Wikihow.com – Wikihow, a popular how-to website, acted quickly by blocking the bot on August 12, 2023, indicating early and proactive measures against content scraping.
- CNN.com – By August 22, 2023, CNN had joined the list of early blockers, emphasizing the media giant’s commitment to protecting its news content.

Growing Trend of Resistance
By September 22, 2023, the percentage of the top 1000 websites blocking GPTBot had risen to 25.9%. This growing trend was driven by fears that allowing AI crawlers unrestricted access could lead to content being repurposed without proper attribution or compensation.
Comparison with Other Bots
Historically, the Common Crawl Bot (CCBot) had faced similar issues. Initially, only 5% of websites blocked CCBot, but this number grew to 13.9% by September 2023, reflecting increasing awareness and resistance to AI crawlers in general. Despite being an older bot, CCBot faced a significant uptick in blockages, driven by the same concerns affecting GPTBot.
Anthropic AI Bot Blockage
In a similar vein, the Anthropic AI bot, though less widely blocked, saw attempts from major sites like Reuters and Corriere.it to restrict its access. By September 11, 2023, Reuters had expanded its block to include both Anthropic AI and Claude-Web bots.

Implications for AI and Web Data
The decision to block GPTBot reflects a growing unease about AI’s role in utilizing web content. Major media and news publishers, including The Guardian, USA Today, Business Insider, Reuters, Washington Post, NPR, CBS, NBC, Bloomberg, CNBC, and ESPN, implemented blocks to protect their digital assets. This action could significantly impact the development of AI models, especially those reliant on current web data.
The blocking of GPTBot has also caught the attention of industry experts. In a tweet, Lily Ray, a notable figure in the SEO community, commented on the potential challenges for SearchGPT:
Yikes… it will be hard for SearchGPT to become a serious threat to Google without access to these sites (and the many other sites that will probably follow suit) https://t.co/Nsqs36LRsW
— Lily Ray 😏 (@lilyraynyc) August 3, 2024
Future Outlook
The rise in blocking GPTBot and other AI crawlers is likely to continue as more websites become aware of the potential risks and benefits. This trend may prompt AI developers to seek new ways to collect data ethically and transparently.
The ongoing dialogue between AI developers and content creators will shape the future of web scraping and data usage, potentially leading to more robust regulations and best practices.
The increasing resistance to AI crawlers like GPTBot has highlighted the importance of choosing trustworthy link-building services for websites aiming to maintain visibility and authority online.
Practical Steps for Web Admins to Block Generative Bots like ChatGPT
For those looking to block GPTBot and other AI crawlers, adding specific directives to the robots.txt file can be an effective measure. Here’s an example:
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
This simple addition can prevent these bots from indexing and using your content without permission.
Key Takeaways
- Over a quarter of the top 1000 websites are now blocking GPTBot, highlighting significant pushback against AI content scraping.
- High-profile publishers like NYTimes and Amazon are leading the charge, setting a trend for others to follow.
- Website administrators can use simple robots.txt directives to control which bots access their content, ensuring greater control over their digital assets.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.