Nearly 8 in 10 of the largest news websites in the UK and the US have moved to block AI training bots, marking a decisive moment in the relationship between publishers and generative AI companies.
The majority of leading news publishers on both sides of the Atlantic are no longer allowing their content to be freely accessed by AI systems for training or live retrieval.
New data shared with Press Gazette shows that 79% of the top news sites in the UK and US are blocking at least one AI crawler associated with model training.
The findings come from an analysis by digital PR platform Buzzstream, which reviewed a combined and deduplicated list of the 50 largest news websites in each country.
The list includes some of the most influential media organizations in the world, making the trend difficult to dismiss as experimental or symbolic.
Training Bots Are Being Shut Out First
The strongest resistance is directed at bots used specifically to train large language models. These include OpenAI’s GPTBot, Anthropic’s ClaudeBot, Applebot-Extended, Google-Extended, and Common Crawl’s CCBot.
Among the top 100 sites studied, more than three-quarters have blocked at least one of these crawlers. Anthropic’s training bot and CCBot face the highest level of restriction, with access permitted by fewer than ten of the largest publishers.
This pattern reflects a growing consensus among publishers that unrestricted training access offers little return. AI systems absorb content at scale, yet rarely send users back to the original source in meaningful numbers.
Live Search Access Is Treated More Carefully
While training bots are widely blocked, publishers are taking a more selective approach to real-time retrieval crawlers. These bots determine whether AI tools such as ChatGPT or Perplexity can pull live information from a site to answer user questions.
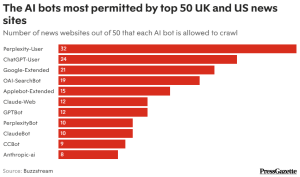
About 71% of major publishers are blocking at least one of these live search bots, including ChatGPT-User, Claude-Web, Perplexity-User, and OAI-SearchBot.
However, some publishers still allow limited access, viewing it as a possible source of visibility or brand presence.
Perplexity-User is the most widely permitted, followed by ChatGPT-User. The distinction suggests that publishers are not rejecting AI outright but are attempting to draw clearer boundaries around how their content is used.
Which Publishers Have Taken the Hardest Line
Roughly one-third of the top 50 publishers reviewed have blocked every AI bot included in the analysis. That group includes the BBC, The New York Times, The Wall Street Journal, NBC News, Sky News, AP News, Business Insider, BuzzFeed, HuffPost, and Newsweek.
At the other end of the spectrum, a small group of publishers allows access to all 11 AI crawlers studied. These include Fox News, Politico, Substack, The Independent, GB News, and the Drudge Report.
The split highlights how uneven the industry response remains, even as the overall direction becomes clearer.
Why Publishers Say the Trade-Off No Longer Works
Harry Clarkson-Bennett, SEO director at The Telegraph, said publishers see little incentive to allow AI bots to crawl their sites because the exchange is fundamentally one-sided.
Large language models do not behave like search engines. They do not reliably pass referral traffic back to publishers, and their responses are generated within closed interfaces. At the same time, publishers remain dependent on traffic to sustain advertising and subscription models.
Without licensing arrangements or revenue sharing, many editors and executives see blocking as a rational defensive move.
“It Is Never Too Late to Block”
Speaking at the IAB UK Techtonic event in London, IAB Tech Lab CEO Anthony Katsur addressed a common concern among publishers that blocking now would have little effect because AI models have already been trained.
That assumption, he said, is wrong.
Modern AI systems rely on retrieval-augmented generation, meaning they regularly return to the web to refresh and verify information. Content must be recrawled to remain accurate, current, and useful. As a result, publishers still have leverage.
Katsur urged publishers who have not yet acted to do so, emphasizing that repeated access is essential for AI systems to stay relevant.
Blocking Is Imperfect, but Still Matters
Robots.txt remains the primary tool publishers use to restrict AI crawlers, but it is far from flawless. Katsur noted that many publisher files contain errors, misconfigurations, or outdated directives that weaken enforcement.
Even when properly implemented, robots.txt relies on voluntary compliance. AI companies can ignore the rules or use third-party services to scrape content indirectly. Despite these limitations, publishers continue to use blocking as a signal of intent and a first line of control.
Google Extended Adds Another Layer of Complexity
Google’s Extended crawler gives publishers the option to block their content from being used for AI training while remaining visible in Google Search. It applies to products such as Gemini and Vertex but does not prevent inclusion in Google’s AI Overviews.
To avoid AI Overviews entirely, a publisher would need to block Googlebot itself, which would remove the site from search indexing. This creates a difficult choice between visibility and control.
The Buzzstream data shows US publishers are far more likely than UK publishers to block Google Extended, suggesting a more aggressive stance in the American market.
A Push Toward New Access Models
Beyond blocking, the IAB Tech Lab is working on an alternative framework known as Content Monetisation Protocols.
The goal is to replace uncontrolled crawling with structured access, using open APIs that allow publishers to set terms, protect copyright, and provide content in formats that are easier for AI systems to use responsibly.
Early discussions have included Google, Microsoft, and Meta. However, Katsur noted a lack of engagement from companies such as OpenAI, Anthropic, and Perplexity, raising questions about whether voluntary standards can gain traction.
What This Signals for the Industry
The scale of blocking now underway suggests this is no longer a fringe concern. Publishers are reassessing long-standing assumptions about discovery, distribution, and value exchange in an AI-driven environment.
Rather than waiting for legal clarity or regulatory intervention, many are taking direct action.
Whether this leads to licensing deals, collective bargaining, or deeper standoffs remains uncertain. What is clear is that access to journalism is no longer being treated as a given.
Key Takeaways
- Most major news publishers now block at least one AI training crawler.
- Economic imbalance remains the central reason for blocking decisions.
- Real-time retrieval bots are treated differently from training crawlers.
- Blocking AI bots is still effective because systems repeatedly recrawl content.
- Publishers are exploring collective action and alternative access frameworks.

Zulekha
AuthorZulekha is an emerging leader in the content marketing industry from India. She began her career in 2019 as a freelancer and, with over five years of experience, has made a significant impact in content writing. Recognized for her innovative approaches, deep knowledge of SEO, and exceptional storytelling skills, she continues to set new standards in the field. Her keen interest in news and current events, which started during an internship with The New Indian Express, further enriches her content. As an author and continuous learner, she has transformed numerous websites and digital marketing companies with customized content writing and marketing strategies.