Despite being blocked from crawling by robots.txt, Google continues to index pages, leaving many webmasters puzzled and frustrated.
Recent insights from John Mueller, Google’s Senior Webmaster Trends Analyst, reveal why these blocked pages still appear in search results and what site owners can do to manage the issue.

Why Blocked Pages Aren’t Staying Hidden
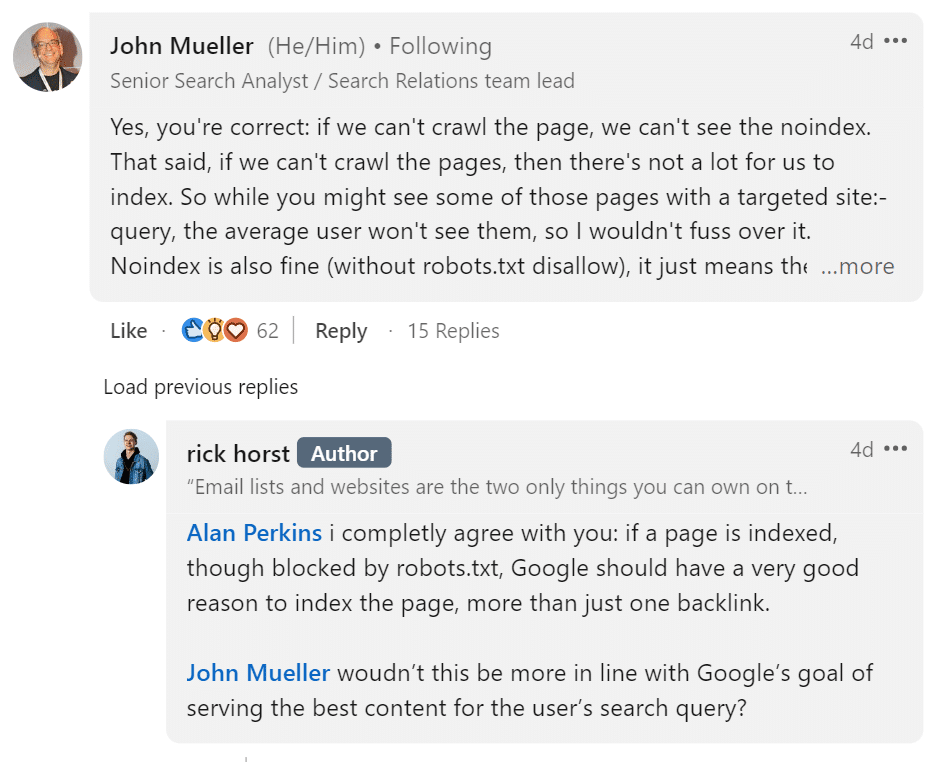
Rick Horst highlighted the mystery surrounding blocked pages showing up in search results. He observed that pages on his website that were supposed to be blocked by robots.txt and noindex tags were still being indexed by Google. These weren’t just any pages—they included query parameter URLs, such as ?q=xyz, which are often used dynamically on websites and generally aren’t intended to be indexed.
John Mueller addressed this issue directly. He explained that while Googlebot can’t crawl pages that are blocked by robots.txt, it can still discover and index those pages through links. If other pages, either on the same website or elsewhere on the web, link to a blocked page, Google may still include that page in its index based solely on the URL, even without seeing the content.
Mueller emphasized that the presence of these pages in Google’s index might show up in specific search queries, especially when using the site: search operator, but he reassured webmasters that the average user would likely never encounter them in general search results. While it may seem alarming to see these pages indexed, it typically doesn’t impact a site’s performance or visibility in the broader search context.
Why Google’s Indexing Quirks Matter for Webmasters
Mueller’s explanation indicates that these occurrences don’t generally harm a site’s SEO rankings or visibility. The fact that Google indexes some disallowed pages doesn’t necessarily mean that the rest of your content will be affected. Google’s algorithms are sophisticated enough to handle these exceptions without penalizing the entire site.
However, unexpected page indexing can still pose significant challenges. Sensitive content, outdated information, or pages meant to be hidden from the public eye could inadvertently become visible, leading to potential reputational risks or exposure to irrelevant material.
Additionally, the lack of reliable diagnostic tools makes it harder for webmasters to effectively manage and troubleshoot these issues.
The site: search operator, commonly used by SEO professionals to check what pages Google has indexed from their website, turns out to be less reliable than previously thought.
Mueller pointed out that this operator doesn’t connect to Google’s main search index, meaning that the results shown through this tool aren’t necessarily reflective of what’s actually being indexed. This revelation complicates the process of diagnosing and fixing indexing issues, requiring webmasters to rely on more accurate tools and methods.
Google and Blocked Content
The challenges of managing what Google indexes have been a constant concern for webmasters since the early days of search engine optimization. The tools provided to manage this, such as robots.txt and noindex tags, have always come with limitations.
Historically, Google has advised against using robots.txt to block pages you don’t want to be indexed, primarily because this method prevents Googlebot from crawling the page and seeing the noindex directive.
This issue reflects the extensive, persistent tussle within the SEO community to find the most effective ways to control content visibility. As search engines have grown more complex, so too have the strategies required to manage how content is indexed and ranked.
The interplay between robots.txt, noindex tags, and Google’s indexing processes has led to an ever-evolving landscape of best practices, with webmasters needing to stay on top of the latest developments to maintain control over their sites.
Mueller’s comments are just the latest in a long line of clarifications and updates from Google about how its search engine interacts with blocked content. These insights accent the need for ongoing education and adaptation in the world of SEO, as even minor missteps can lead to unintended consequences.
Adapting to Google’s Evolving Indexing Methods
Webmasters will need to adjust their strategies in response to these revelations. John Mueller’s advice suggests that simply blocking pages with robots.txt is no longer sufficient to control what gets indexed. Instead, webmasters should ensure that noindex tags are visible to Googlebot, avoiding robots.txt disallows for pages they want to keep out of the index.
This shift in strategy will require a more nuanced approach to managing content. Webmasters must carefully consider how their pages are linked and ensure that sensitive or irrelevant content isn’t accidentally exposed through external or internal links. The challenge will be to balance the need for comprehensive site management with the desire to keep certain pages hidden from search results.
Looking ahead, Google may continue to refine its indexing processes to reduce the likelihood of disallowed pages being indexed. However, until such advancements are made, webmasters must remain proactive in monitoring their sites and addressing any issues. Routine checks of Google Search Console reports and a thorough understanding of how Googlebot interacts with your site’s content will be essential for maintaining control over your site’s visibility.
How Webmasters Can Protect Their Content
Here are a few practical steps webmasters can take to better protect their content from being indexed by Google unintentionally, ensuring more control over what appears in search results.
Keep Noindex Pages Accessible for Googlebot
One of the key takeaways from Mueller’s comments is the importance of ensuring that Googlebot can access pages with noindex tags. If a page is blocked by robots.txt, Google won’t be able to see the noindex directive, potentially leading to unintended indexing. Avoid using robots.txt to block pages you want to keep out of the search index; instead, allow Googlebot to crawl the page and see the noindex tag.
Regularly Review Google Search Console
Google Search Console remains one of the most valuable tools for webmasters looking to manage their site’s visibility. Regularly reviewing reports from the Search Console can help you catch any unexpected indexing of blocked pages. While these reports, such as “Indexed though blocked by robots.txt,” may not indicate critical issues, they provide useful insights that can help you fine-tune your site’s configuration and avoid any potential exposure of sensitive content.
Be Cautious with Diagnostic Tools
The site: search operator has long been a go-to tool for webmasters looking to diagnose indexing issues. However, as Mueller pointed out, this operator doesn’t connect to Google’s primary search index, making it unreliable for understanding what Google has truly indexed from your site. Webmasters should be cautious when using this tool and seek out more accurate methods for diagnosing indexing issues.
Control Your Links
One of the key factors that can lead to unintended indexing is the presence of links to blocked pages. Whether these links are internal or external, they can lead Google to discover and index pages that you intend to keep hidden. Webmasters should regularly review their site’s link structure and external backlinks to ensure that no unwanted pages are being exposed through these links.
Stay Updated on Best Practices
Google’s guidelines and best practices for SEO and content management are constantly evolving. Webmasters must stay informed about the latest developments to ensure their strategies remain effective. Staying updated also ensures you avoid common pitfalls and optimize your site for visibility and control.
Key Takeaways
- Google can index pages blocked by robots.txt if they are linked from other sources, despite not being able to crawl them.
- John Mueller advises that using robots.txt to block noindex pages is ineffective; the noindex tag must be visible to Googlebot.
- Site: search operator is unreliable for diagnosing indexing issues, and regular monitoring via Google Search Console is essential.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.