Key Takeaways
- Traditional LLMs can’t see images — they process text tokens only.
- To interpret visuals, AI uses vision models that convert images into “tokens” the same way words are tokenized.
- This process, known as image tokenization and embedding, allows multimodal models (like GPT-4V or Gemini) to combine vision + language reasoning.
- For SEOs, alt text, captions, and structured data remain vital to make images machine-readable.
- The future is multimodal indexing — where search and AI tools understand both words and visuals together.
Generative AI models like ChatGPT, Gemini, and Claude can now analyze not only words but also images, charts, and videos. But the question remains: can large language models (LLMs) actually read the images embedded inside a webpage?
The answer: standard LLMs can’t but multimodal LLMs can.
Traditional text-only LLMs are blind to visual content. They rely entirely on textual cues such as captions or alt-tags. But the latest generation — Multimodal LLMs (MLLMs) — use specialized vision components that transform pixel data into tokens, enabling AI to interpret what’s inside an image alongside the surrounding text.
For marketers and SEOs, this changes how we think about optimization. It’s no longer just about keywords; it’s about content accessibility across modalities. As Google, Bing, and Perplexity move toward AI-driven search, the way images are described, tagged, and structured will directly affect visibility.
Understanding the Basics: What LLMs Actually Do
LLMs, or Large Language Models, are designed to process text — not images.
They predict language patterns, complete sentences, and reason about information based on words only.
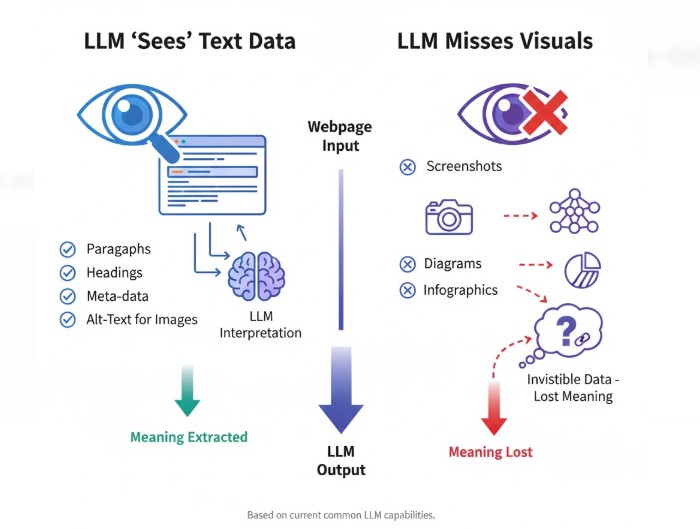
When an LLM processes a webpage:
- It reads paragraphs, headings, meta-data, and alt-text.
- It does not interpret embedded visuals unless they’ve been described in text form.
- Screenshots, diagrams, and infographics become invisible data — lost meaning.
That’s why two websites with identical copy but different image content might be treated identically by a text-only model. To bridge that gap, AI systems needed a new kind of intelligence: multimodality.
From Text to Vision: The Rise of Multimodal Models
Modern Multimodal LLMs (MLLMs) are the next evolution — capable of processing text, images, audio, and video together.
Key Examples
- OpenAI GPT-4V (Vision) – understands screenshots, graphs, and photos.
- Google Gemini 1.5 Pro – blends text and image analysis seamlessly.
- Claude 3 Opus – interprets charts and PDFs with embedded visuals.
- Mistral MM1 – open-source multimodal architecture for enterprise use.
These systems use a shared token space that allows language and vision to coexist — giving rise to context-aware AI that can interpret not just what an image shows but why it matters in the page context.
So, Can LLMs Read Images Inside a Webpage?
Let’s separate theory from reality.
1. Traditional LLMs (Text-Only)
- Cannot interpret image pixels.
- Depend entirely on textual cues like <alt> tags and captions.
- Images without descriptive text are effectively invisible.
Example:
An infographic with no title, alt text or description adds zero value to an AI summary.
2. Multimodal LLMs (Vision + Language)
- Convert images into visual tokens that the model can process alongside text.
- Extract meaning via Vision Transformers (ViT) or CLIP encoders.
- Perform reasoning that connects visuals with surrounding paragraphs.
Example:
The same infographic, when fed into GPT-4V, can be “read”: it identifies the headline, colors, and chart structure — even the embedded text — allowing it to contextualize your blog’s message.
3. Enterprise & SEO Implications
Businesses are beginning to use these pipelines to:
- Extract insights from screenshots and infographics.
- Audit on-page visuals for accessibility and metadata.
- Build knowledge graphs combining visual + textual entities.
This is the new layer of SEO intelligence: Visual Data Indexing.
Technical Deep Dive: How LLMs Actually Process Images
Multimodal Large Language Models (MLLMs) don’t “see” an image the way humans do.
Instead, they translate it into numbers that represent visual meaning — a process powered by tokenization and embedding.
Here’s what happens behind the scenes 👇
Step 1: Image Tokenization
- The image is split into a grid of small patches (e.g., 16 × 16 pixels).
- Each patch becomes a numerical vector (embedding) representing color, shape, and texture.
- Positional encoding preserves spatial relationships between patches.
These vectors are treated like “words” — they’re visual tokens that an LLM can understand.
Step 2: Vision Encoding
A Vision Transformer (ViT) or model like CLIP extracts high-level features from the image, similar to how a language model extracts meaning from sentences.
It creates embeddings that capture what’s in the image — objects, patterns, text, and relationships.
Step 3: Modality Connection
Because text and image data are different types, a modality connector (often a Multilayer Perceptron or cross-attention module) bridges the gap.
It maps visual embeddings into the same semantic space as text embeddings, allowing the model to process both together.
Step 4: Unified Processing
Once the visual tokens enter the transformer, the model’s self-attention mechanism can analyze how image and text tokens relate.
For example:
- Understanding that an image of a bar chart illustrates the sentence above it.
- Linking a product photo to its description.
- Extracting text within images (via integrated OCR).
Step 5: Enhanced Capabilities
This integration unlocks advanced reasoning:
- Contextual Understanding: Relating visuals to written context.
- Visual Question Answering: Responding to questions about images.
- Image Captioning: Describing images automatically for accessibility.
- Text Extraction: Reading embedded text directly from images.
In essence, an MLLM doesn’t just parse HTML — it converts all elements (text + visuals) into a unified token stream, producing a holistic interpretation of the page.
Why This Matters for Marketers and SEOs
1. Images Without Text Are Invisible
Until multimodal indexing becomes mainstream, search engines and AI crawlers depend on textual data.
If your visuals contain key stats or charts but no description, they vanish from AI summaries and search snippets.
➡ Fix: Add descriptive alt-text and captions.
2. AI Overviews Need Textual Signals
Google’s AI Overviews pull from semantic content, not pixels.
If your infographic explains “Affordable SEO pricing tiers,” ensure the same content exists as text in the post.
3. Accessibility = Visibility
Adding meaningful image descriptions isn’t just about compliance; it makes your content discoverable.
Alt-text and structured data help both screen readers and AI agents interpret visuals.
4. Future-Proof SEO Strategy
Soon, search crawlers using Gemini or GPT-powered vision models will read your visuals.
The better your images are described and semantically aligned with on-page text, the higher your AI visibility score will be.
How to Make Your Images “Readable” by AI
Write Descriptive Alt Text
Use natural language to describe both what’s in the image and why it matters.
Add Captions and Context
Captions are among the most-read parts of a page — they reinforce keyword relevance and topic authority.
Use Structured Data
Implement ImageObject schema to give search engines explicit metadata.
{
“@context”: “https://schema.org”,
“@type”: “ImageObject”,
“contentUrl”: “https://www.stanventures.com/images/affordable-seo-guide.jpg”,
“description”: “Infographic comparing ROI across affordable SEO packages for small businesses in 2025.”,
“author”: “Stan Ventures”
}
Ensure Visual Clarity
High-contrast, text-legible visuals improve OCR accuracy. Avoid over-compressed images.
Duplicate Critical Data in Text
If your infographic includes statistics, repeat them in paragraph form below the image.
The Technology Powering Multimodal AI
| Component | Function | Example Tools |
| OCR (Optical Character Recognition) | Reads text inside images | Google Vision API, AWS Textract |
| CLIP / ViT | Converts images into embeddings | OpenAI CLIP, ViT by Google |
| Cross-Attention Layers | Merge visual and text tokens | Used in GPT-4V, Gemini |
| Vector Databases | Store and query embeddings | Pinecone, Weaviate, FAISS |
Together, these build the multimodal ecosystem driving the next wave of AI search.
Future Outlook: Where We’re Headed
AI That Truly Sees
In the next two years, expect image-aware indexing in Google Search. Visuals will contribute directly to topical authority and entity relationships.
Visual Search + Generative Summaries
Search engines will fuse visual search (Lens, Bing Visual Search) with generative AI summaries. Your image could become both a ranking factor and a featured explanation.
Answer Engine Optimization (AEO) Evolves
As Answer Engines consume multimodal content, optimizing for how AI explains your visuals will be the next SEO frontier.
Agency Opportunity
Forward-thinking agencies like Stan Ventures can offer AI-Readiness Audits — checking whether client images are machine-interpretable and aligned with AEO standards.
Quick Recap
- Traditional LLMs can’t read image pixels.
- Multimodal LLMs tokenize visuals into embeddings that interact with text.
- Gemini’s architecture (patching, embedding, modality connectors) defines how AI “sees.”
- Marketers must keep alt-text, captions, and schemas consistent.
- The future of SEO is multimodal — where text and visuals are inseparable for ranking.
The era of AI that truly “sees” is here. While traditional LLMs could only interpret words, multimodal AI now reads the full story — images included.
For marketers and SEOs, this means your visual strategy is now part of your search strategy.
At Stan Ventures, we help brands future-proof their digital presence — optimizing not just for keywords, but for the AI ecosystems interpreting them. Book a Free AI-SEO Consultation
and find out whether your website is ready for the multimodal future.
FAQ
Q1. Can ChatGPT or Gemini read images in blog posts?
Yes — if you’re using a multimodal version like GPT-4V or Gemini 1.5 Pro. Text-only models ignore image pixels.
Q2. Does this change Google SEO right now?
Not yet, but Google’s Gemini indexing experiments suggest multimodal signals will influence ranking soon.
Q3. Should I rewrite every infographic in text?
No, just include descriptive text or a short data summary below it.
Q4. Can AI extract text from images automatically?
Yes, through OCR (Optical Character Recognition). Gemini and GPT-4V can read embedded words and integrate them into summaries.
Q5. How can Stan Ventures help businesses prepare?
We run AI Visibility Audits that analyze whether your content — text, visuals, and metadata — is ready for AI-driven discovery.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.
