In a Google Search Central Lightning Talk, Martin Splitt of Google shared a comprehensive breakdown of how to use robots.txt, robots meta tags, and HTTP headers to control what search engines can access and index on your website.
These tools are indispensable for website owners who want to safeguard sensitive content, optimize search performance, and avoid common SEO mistakes.

Splitt also tackled frequent questions, like why Googlebot sometimes crawls restricted pages, when to use “noindex” versus “disallow,” and how to ensure your setup works correctly.
Let’s explore his insights in detail.
What Is Robots.txt, and Why Is It Important?
A robots.txt file is a critical tool for controlling search engine access to your website. Placed in the root directory (e.g., example.com/robots.txt), it acts as a rulebook for search engines, defining which pages should or shouldn’t be crawled. Managing this file correctly can improve SEO performance, optimize crawl budget, and protect sensitive data.
Key Benefits of Robots.txt
- Optimize Crawl Budget: Direct crawlers toward high-value pages and away from low-priority content.
- Protect Sensitive Areas: Prevent indexing of admin panels, staging environments, or private directories.
- Reduce Server Load: Limit bot activity on resource-heavy pages.
- Guide Search Engines: Specify sitemap locations and indexing rules.
How Robots Meta Tags and HTTP Headers Offer Precision
While robots.txt blocks access to entire sections of a site, robots meta tags and X-Robots-Tag HTTP headers offer page-level control over indexing and crawling.

Key Uses of Robots Meta Tags:
- Noindex: Prevent a page from appearing in search results while still allowing bots to crawl it.
- Nofollow: Stop bots from following links on a page.
- Snippets and Translations: Control how much of your content appears in search previews or whether translations are displayed.
- Bot-Specific Rules: Customize behavior for individual bots, such as Googlebot-News.
X-Robots-Tag HTTP Header:
This server-side directive works similarly to robots meta tags but is ideal for controlling access to non-HTML files like PDFs, videos, or images.
Noindex vs. Disallow: When to Use Each
Splitt clarified the distinction between noindex and disallow, two commonly confused directives:
Noindex vs. Disallow: When to Use Each
| Directive | Purpose | Example Use Case |
|---|---|---|
| Noindex | Prevents a page from appearing in search results but allows Google to crawl it. | Duplicate pages, outdated content. |
| Disallow | Prevents bots from crawling the page entirely. | Admin areas, internal search result pages. |
Use Noindex:
When you want a page to remain accessible but hidden from search results.
- Example: Outdated blog posts or duplicate pages.
- Implementation: Use a robots meta tag or X-Robots-Tag HTTP header.
<meta name=”robots” content=”noindex”>
Use Disallow:
When you don’t want bots to access a page at all.
- Example: Admin dashboards, staging environments, or private directories.
- Implementation: Add a rule in robots.txt.
User-agent: *
Disallow: /admin/

Key Difference:
- Noindex keeps pages out of search results but still allows crawling.
- Disallow prevents both crawling and indexing, but Google might still discover the URL through external links.
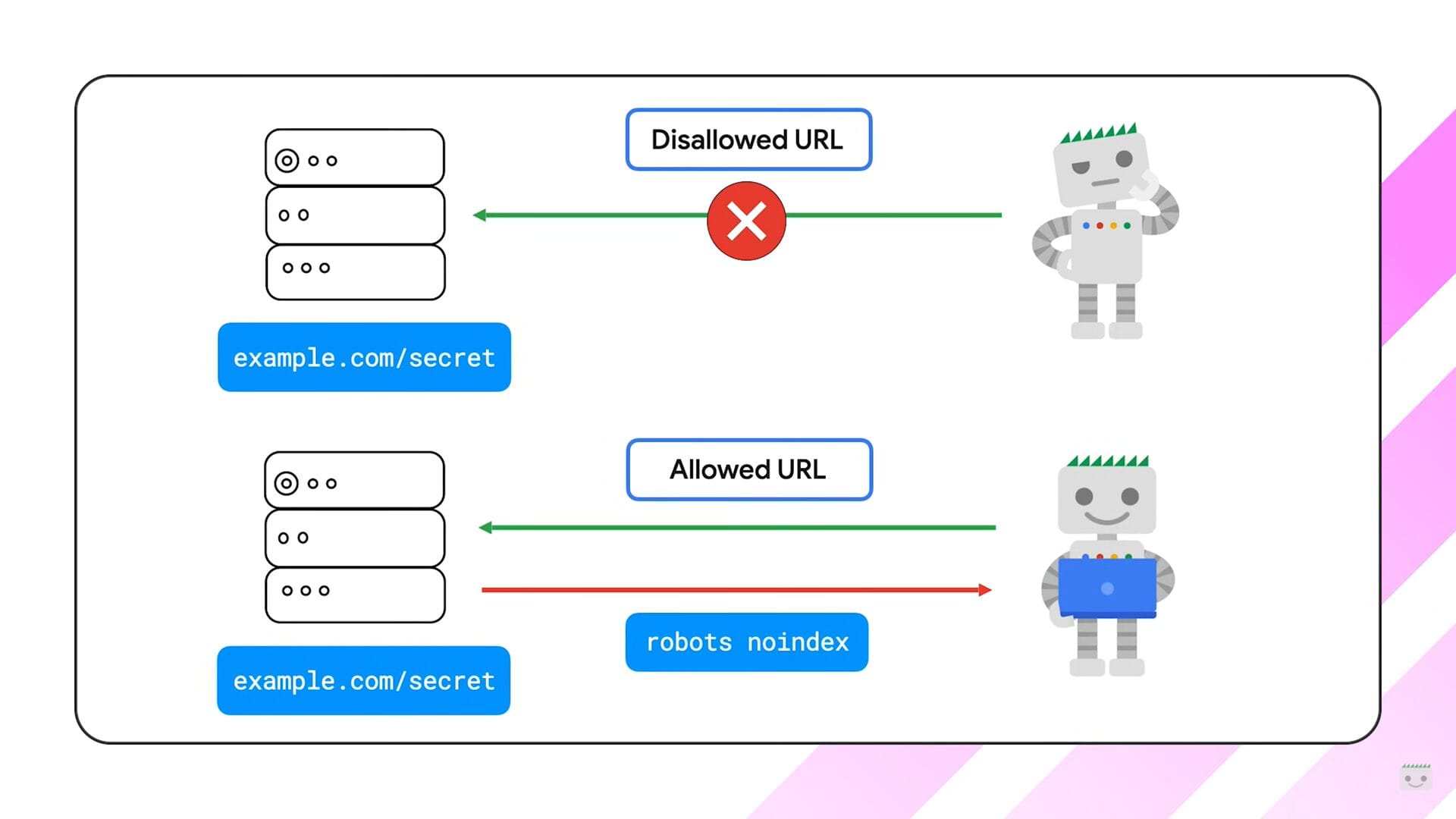
Why Is Googlebot Crawling Restricted Pages?
Splitt addressed a frequent question: Why might Googlebot still crawl pages you thought were restricted?
The Problem:
If you block a page using robots.txt, Googlebot may still discover it through links or other sources. However, because the bot can’t access the page, it won’t see any meta tags (like “noindex”) or HTTP headers.
As a result:
- The page might still appear in Google’s index.
- Only limited information—like the URL or anchor text from links—will be displayed.
The Fix:
- Use noindex meta tags or X-Robots-Tag for pages you want to be hidden from search results.
- Do not block those pages in robots.txt, as it prevents Googlebot from reading the “noindex” directive.
This distinction ensures bots can interpret your indexing instructions correctly.
Common Robots Mistakes and How to Avoid Them
Here are some common mistakes site owners make when using robots.txt and meta tags, along with tips on how to avoid them for optimal site management:
Blocking Noindex Pages in Robots.txt: If you use robots.txt to block Googlebot from accessing a page, it won’t see the noindex meta tag, leading to unintended indexing.
Misconfigured Rules: Overlapping or contradictory directives in robots.txt can confuse bots, resulting in crawling inefficiencies.
Ignoring Testing Tools: Without testing, you might accidentally block high-value pages or expose sensitive information.
Best Practices:
- Keep robots.txt rules simple and precise.
- Use noindex or disallow thoughtfully, depending on your goal.
- Test your setup regularly to ensure it works as intended.
How to Test Robots.txt
Splitt emphasized the importance of testing robots.txt to validate its effectiveness. Google offers two powerful tools for this purpose:
Google Search Console Robots.txt Tester:
- Simulate how Googlebot interprets your robots.txt file.
- Identify and fix syntax errors.
Open-Source Robots.txt Tester:
- A lightweight tool for developers to refine their robots.txt configuration before deployment.
Regular testing ensures your directives align with your site’s goals.
Robots.txt in Practice
When implemented correctly, robots.txt and related tools can significantly improve your website’s performance:
- Boost SEO: Guide search engines to your most valuable content.
- Enhance Security: Prevent sensitive data from being crawled or indexed.
- Save Resources: Reduce unnecessary bot traffic on your server.
A Short History of Robots.txt
The robots.txt protocol was introduced in 1994 to help site owners manage how early web crawlers interacted with their websites. Over time, it has become a standard tool for SEO and site management. Despite its simplicity, it remains one of the most misused tools, often leading to unintended SEO consequences.
What’s Next for Robots.txt Management?
As AI-powered bots grow more common, managing how they interact with websites will become increasingly important. Splitt suggested that future updates to tools like robots.txt may provide even more nuanced control options. Staying informed will help site owners adapt to these changes effectively.
How to Implement Robots.txt Like a Pro
Let’s look at the key steps and best practices to ensure you’re using robots.txt effectively.
Keep It Simple: Use clear, straightforward rules.
Test Regularly: Use tools like Google Search Console to validate your setup.
Avoid Overlapping Directives: Don’t combine robots.txt blocks with “noindex” meta tags.
Educate Your Team: Ensure everyone involved in site management understands the purpose of these tools.
Stay Updated: Follow Google’s guidelines to adapt to changing search engine behavior.
Key Takeaways
- Robots.txt blocks bots from accessing parts of your site.
- Meta tags provide more granular control over how pages appear in search results.
- Avoid blocking “noindex” pages in robots.txt; Google needs access to see the tag.
- Regular testing prevents accidental SEO errors.
- Staying informed about evolving search technologies is critical for long-term success.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.