Google has updated its documentation to warn site owners against relying on JavaScript to add or remove noindex tags, noting that its crawler may stop processing a page before scripts are ever run.
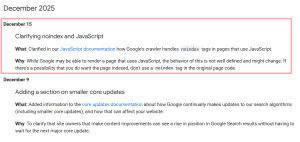
Google has revised its JavaScript SEO basics documentation to clarify how its crawler handles pages that include a noindex directive.
The update was published on December 15, 2025, and directly addresses a common technical SEO practice involving JavaScript-rendered pages.
The company explained that when Googlebot encounters a noindex tag in a page’s original HTML, it may choose not to render the page or execute any JavaScript at all. That means any attempt to later change or remove the noindex directive using JavaScript could fail entirely.
In Google’s words, if a page might need to be indexed, the noindex tag should never appear in the initial page code.
Why JavaScript Is an Unreliable Safety Net
Many modern websites depend on JavaScript to control how content is displayed and managed. Some teams also use JavaScript to dynamically adjust robots meta tags based on conditions such as user state or page type.
Google is now making it clear that this approach carries risk. If the crawler sees noindex early in the process, it may stop before any scripts are evaluated. At that point, whatever JavaScript logic was meant to reverse the directive never runs.
Google also noted that while it can render JavaScript-heavy pages in many cases, that behavior is not guaranteed and could change. Because of that uncertainty, Google recommends keeping indexing decisions simple and explicit in the page’s initial HTML.
SEO analyst Glenn Gabe added further clarity in a post on X, noting that the issue relates to JavaScript rendering rather than any change in Google’s indexing policy and that pages meant to be indexed should not include noindex in the original source code.
To clarify, this is about JavaScript rendering. If you use JS to change the meta robots tag, then understand that Google can skip rendering and not execute JS if it sees a noindex tag in the static html. So if you want a page indexed, then don’t use noindex from the start only to… https://t.co/eRuq2pHd1U
— Glenn Gabe (@glenngabe) December 15, 2025
Teams running complex or JavaScript-heavy sites can easily miss issues like this during routine updates, which is why some organizations turn to professional SEO services to review indexing and crawling signals before they affect search visibility.
What Changed From Earlier Guidance
Earlier versions of the documentation stated that Google skips rendering when noindex is present.
The updated language now says Google may skip rendering, but the outcome for site owners is effectively the same.
The change reflects a more cautious explanation rather than a technical reversal. Google is signaling that relying on JavaScript for core crawling instructions is unsafe, even if it sometimes works.
Why This Matters for SEO Teams
For SEO teams managing large sites, especially those built on JavaScript frameworks, this update highlights a common failure point.
A single misplaced noindex tag in a template or response header can quietly block pages from search results. If teams assume JavaScript will correct that mistake later, they may not notice the issue until traffic drops.
This is particularly relevant for teams handling technical audits, page templates, or large-scale content rollouts. Clear, server-side control over indexing signals remains the most dependable option.
Practical Guidance for Site Owners
Here are a few steps site owners can take to avoid indexing surprises:
- Decide indexing status before the page is served to crawlers.
- Keep noindex directives out of HTML unless the page should never appear in search.
- Avoid JavaScript-based toggles for robots meta tags on important pages.
- Check raw HTML responses, not just rendered views, during audits.
- Treat JavaScript as a layer for user experience, not indexing control.
What to Take From Google’s Update
Google’s message is less about new rules and more about reliability. When it comes to indexing instructions, the crawler responds best to direct, unambiguous signals.
JavaScript remains useful for many aspects of modern web design, but Google is drawing a clear boundary around how much trust site owners should place in it for crawling decisions.
Key Takeaways
-
- Googlebot may stop processing a page as soon as it sees noindex.
- JavaScript changes to indexing directives are not guaranteed to run.
- Pages that might need indexing should never include noindex in raw HTML.
- Client-side fixes cannot replace server-side clarity.
- Simple signals lead to more predictable search visibility.

Zulekha
AuthorZulekha is an emerging leader in the content marketing industry from India. She began her career in 2019 as a freelancer and, with over five years of experience, has made a significant impact in content writing. Recognized for her innovative approaches, deep knowledge of SEO, and exceptional storytelling skills, she continues to set new standards in the field. Her keen interest in news and current events, which started during an internship with The New Indian Express, further enriches her content. As an author and continuous learner, she has transformed numerous websites and digital marketing companies with customized content writing and marketing strategies.