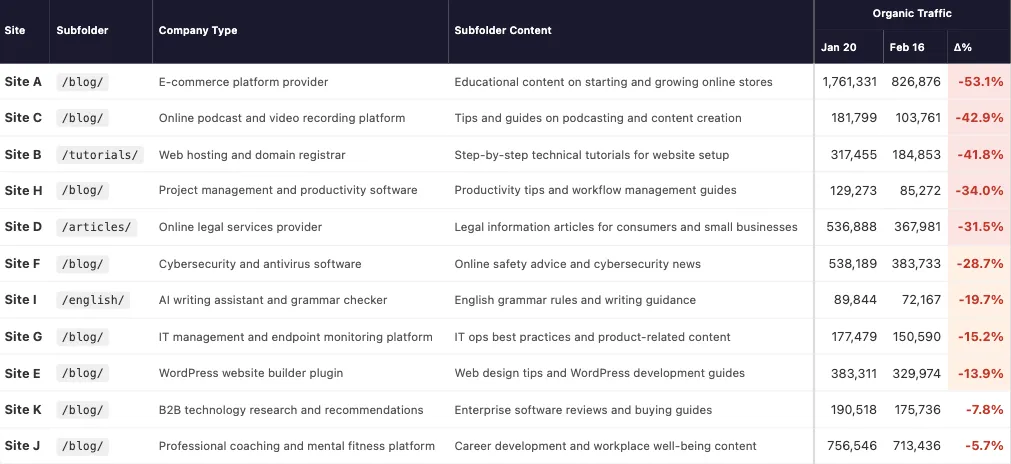
Google’s handling of canonical tags is proving less predictable than many site owners assume, and new case studies show those decisions can ripple beyond search results into AI platforms like ChatGPT, reshaping what content users actually see.
Google has long stated that the rel canonical tag is a suggestion rather than a command. Fresh case studies now reinforce how real and far-reaching that reality can be.
In multiple large-scale sites, Google ignored the preferred canonical URLs set by site owners, selected alternatives it deemed stronger, and indexed those instead. Those choices affected rankings, traffic patterns, user experience, and even what URLs appeared inside AI-generated answers.
The findings were documented by Glenn Gabe, who analyzed several real-world scenarios across complex, high-volume websites.
The examples highlight a common thread. Once Google makes a canonical choice, that decision often becomes the version copied, scraped, or echoed by downstream systems.
Why Rel Canonical No Longer Guarantees Control
Rel canonical was never meant to be a command, and Google has been consistent about that. Senior Search Advocate John Mueller has explained this directly in webmaster office-hour videos, including the one at the 33-minute mark of a recent session where he noted that Google will choose what it believes is the strongest URL even if it conflicts with the site’s preferred canonical.
On a small site, those decisions might be manageable and contained. But on a site with hundreds of thousands or millions of pages, the effects multiply. When Google overrides a canonical tag, it can change which pages receive impressions, clicks, and search traffic. It can shift where engagement is recorded, which URLs are crawled most often, and which are sidelined.
Once Google settles on a canonical, the effects compound. Search results change, performance data shifts, and external platforms pick up the same version. Reversing that momentum is possible, but it rarely happens quickly.
Case Study One: A Hidden Subdomain Becomes the Canonical Winner
The first case involved a subdomain that was intended to remain inaccessible behind a login. A technical failure left it exposed, allowing Google to discover and crawl it.
Once indexed, the subdomain presented URLs that closely matched those on the main site. Google evaluated both sets and began selecting the subdomain URLs as canonical. These pages then replaced the intended URLs in search results and ranked prominently.
The situation worsened due to branding issues. The subdomain displayed a generic favicon instead of the brand’s recognizable icon, undermining trust in the search results. The site owner was unaware of the issue until crawl statistics revealed unexpected activity. By that point, inbound links had already been reassigned internally by Google to the new canonical URLs.
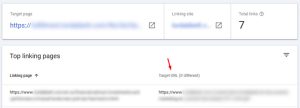
This reassignment created further confusion inside Google Search Console, where links appeared to point to URLs different from their original targets. This behavior, sometimes referred to as link inversion, showed how one canonical issue can trigger a chain reaction across reporting systems.
A fast fix with limits
To regain control quickly, the subdomain was removed from search results using the Removals tool in Google Search Console. Within eight to ten hours, the URLs no longer appeared in the SERPs.
However, the Removals tool only suppresses visibility. It does not remove URLs from the index. Permanent resolution required additional steps, including restricting access and ensuring the URLs could no longer be crawled or served.
The open question remains how quickly Google will reassign canonical status back to the correct URLs and reindex them fully. Canonical recovery is often slower than canonical disruption.
Case Study Two: Google Prefers the Weaker Page
The second example highlights a more subtle but widespread issue. The site offered two related page types. One was designed as the primary destination for search traffic. The other existed mainly to support on-site navigation and deeper exploration.
Rel canonical tags clearly indicated which page should be indexed and ranked. Google chose otherwise.
Across tens of thousands of URLs, Google indexed and ranked the secondary pages instead. These pages provided a less complete experience and were not intended to attract search traffic. Users arriving from search were landing on pages that did not represent the site’s best content.
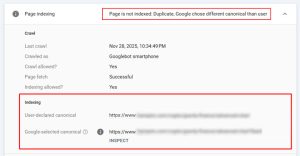
The site owner had no immediate visibility into the issue. Only a detailed analysis of indexed URLs and search performance revealed the scale of the problem.
Stronger signals were required
In this case, rel canonical alone was insufficient. The corrective approach involved applying noindex directives to pages that were never meant to appear in search results. This clarified intent far more effectively than canonical hints.
As Google processed the changes, Search Console data began to show a steady decline in impressions and clicks for the unwanted URLs, confirming that the correction was taking hold.
A Large-Scale International Example With an Unexpected Outcome
The third case involved a site with more than 50 million URLs using hreflang to target multiple countries while serving content in the same language.
For years, Google indexed each country-specific version separately. Then, in a sudden system change, Google canonicalized millions of URLs to a single version located in the site’s core directory.
At first glance, the impact appeared severe. Index coverage dropped sharply for the affected directories, and performance data suggested a major loss in visibility.
What actually happened
Despite canonicalizing the URLs, Google continued to show the correct country-specific versions in search results based on hreflang signals. The pages were visible to users, even though they were not indexed individually.
The confusion stemmed from how Google Search Console reports data. Impressions and clicks were attributed only to the canonical URLs, making it appear as though traffic had disappeared from the localized versions.
This behavior, often described as the hreflang magic trick, is intentional. It allows Google to consolidate indexing while still serving geographically relevant URLs in search results.
When Canonical Issues Spill Into AI Search
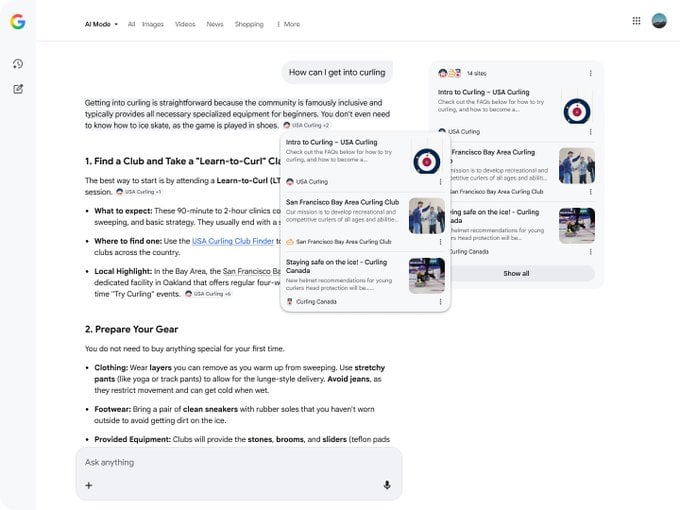
The most revealing insight came when these same canonical selections began appearing in AI-generated answers.
URLs chosen by Google as canonical surfaced inside ChatGPT responses, even when site owners had explicitly designated different URLs as preferred. Repeated testing across multiple sites showed consistent patterns.
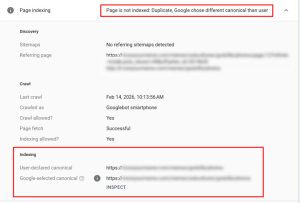
This suggests that AI platforms continue to depend heavily on Google’s indexed results. When Google overrides canonical signals, those decisions cascade into AI systems, amplifying errors and extending their reach.
For publishers, this means canonical issues now affect how content is summarized, referenced, and recommended beyond traditional search results.
What This Means for Large Websites Today
Canonical management can no longer be treated as a set-and-forget task. On large and complex sites, it requires continuous monitoring and cross-team coordination.
Rel canonical remains useful, but it should be supported by stronger signals when necessary. Pages that should never appear in search results should be explicitly blocked using noindex or access restrictions. Crawl stats and index coverage reports should be reviewed regularly to catch anomalies early.
Equally important is internal communication.
SEO, engineering, and content teams must share a clear understanding of which URLs matter and why. When canonical confusion arises, delays in alignment can allow problems to spread across millions of pages and into external platforms.
Key Takeaways
- Rel canonical is advisory, not decisive. Google will select the URL it trusts most, even when that conflicts with explicit signals from the site.
- Canonical mistakes multiply fast on large websites. A single issue can redirect indexing, rankings, and user traffic across thousands or millions of pages.
- Search Console can mask what is really happening. Traffic may shift to a different canonical without disappearing, creating false signals of decline.
- AI platforms mirror Google’s choices. When Google favors the wrong URL, that version can surface in AI answers and extend the impact further.
- Canonical intent must be enforced, not suggested. Pages that should never rank require noindex, access controls, or structural fixes, not just tags.

Zulekha
AuthorZulekha is an emerging leader in the content marketing industry from India. She began her career in 2019 as a freelancer and, with over five years of experience, has made a significant impact in content writing. Recognized for her innovative approaches, deep knowledge of SEO, and exceptional storytelling skills, she continues to set new standards in the field. Her keen interest in news and current events, which started during an internship with The New Indian Express, further enriches her content. As an author and continuous learner, she has transformed numerous websites and digital marketing companies with customized content writing and marketing strategies.