Google has officially revealed a new document on how we search by voice: Speech-to-Retrieval (S2R).
Unlike traditional systems that first convert spoken queries into text, S2R bypasses transcription entirely. Instead, it directly interprets your voice and fetches results based on intent, not just words.
For years, voice search has relied on automatic speech recognition (ASR), a system that tries its best to capture what you said, turn it into text, and then pass it to search engines.
But what happens if the system mishears you? A single misinterpreted letter can flip meaning entirely.
Google Research scientists Ehsan Variani and Michael Riley explained the shift in an October 2025 blog post, calling S2R not just a technical change but a “fundamental architectural and philosophical shift.”
Why Was Voice Search Struggling Until Now?
Voice search is not new. Many of us already ask Google for the weather, the nearest coffee shop, or a quick fact about history. The problem is accuracy.
Take Google’s own example: if you ask about Edvard Munch’s painting The Scream, the ASR system has to hear you perfectly.
If it mistakenly hears screen painting instead, you are suddenly reading tutorials about wall stencils instead of one of the most iconic artworks in history.
This problem, known as error propagation, means that a small mistake in transcription can derail the entire retrieval process.
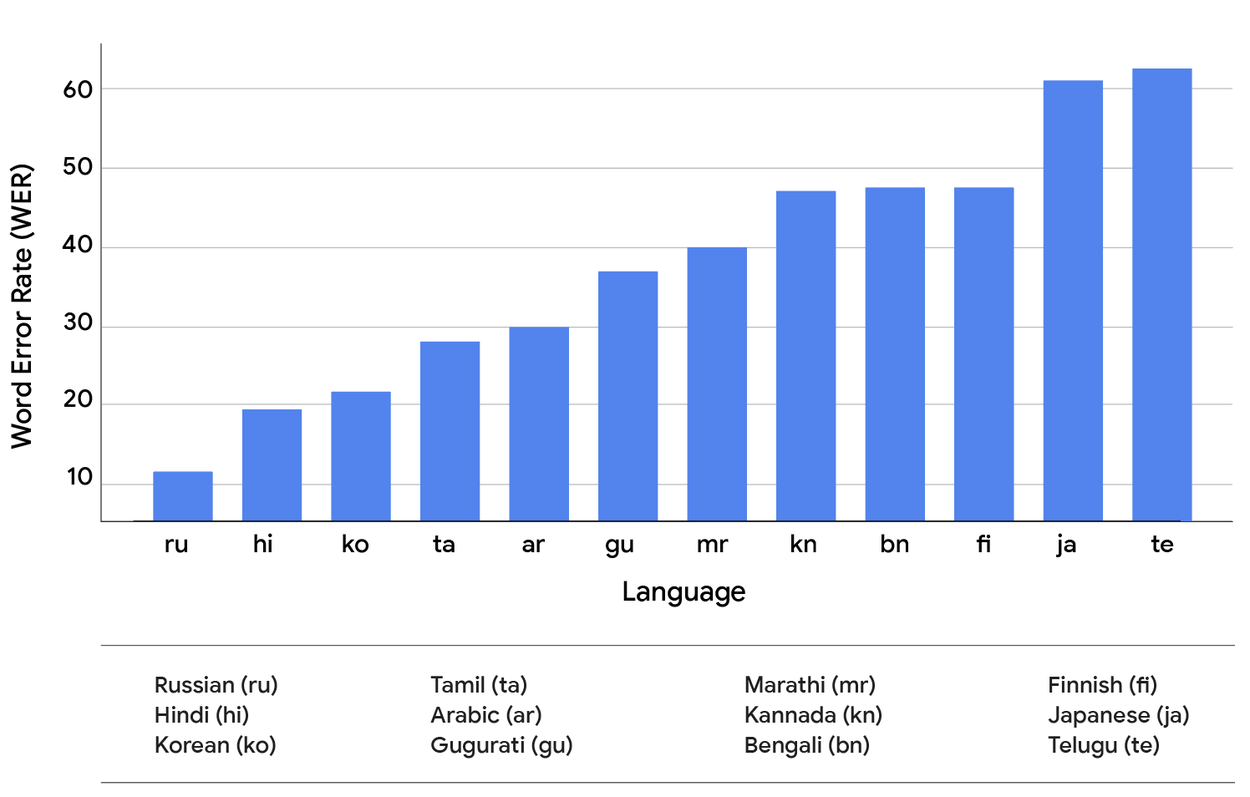
And while ASR has improved massively over the years, perfection is still elusive. Word Error Rates (WER) vary by language, accent and context.
What Makes Speech-to-Retrieval (S2R) Different?
The magic of S2R lies in skipping the fragile transcription step. Instead of asking, “What words did the user say?” it asks a bigger question: “What information is the user seeking?”
Here is how it works:
- When you speak, your audio is processed by an audio encoder, which translates your voice into a semantic vector, a numerical representation of intent.
- At the same time, documents in Google’s index are represented by a document encoder.
- The system then compares the query vector with document vectors, pulling out the most relevant matches.
This means your intent, not just the exact words you said guides the results. In practice, it reduces the impact of tiny transcription errors and makes search more natural.
How Did Google Test the Limits of Current Voice Search?
To prove why S2R is necessary, Google ran an important experiment. They created two versions of the traditional cascade model:
- Cascade ASR – the real-world system, where voice is transcribed into text and then searched.
- Cascade Groundtruth – a “perfect” system, where human-annotated transcripts were used, simulating flawless speech recognition.
Both were tested on the Simple Voice Questions (SVQ) dataset, which includes short queries across 17 languages and 26 locales.
The results were telling:
- Even when ASR transcription was almost perfect, retrieval quality didn’t always improve.
- Mean Reciprocal Rank (MRR), a measure of how well systems surface the right answer, lagged significantly behind the groundtruth system.
- The performance gap showed that voice search quality is capped by transcription errors, no matter how advanced the ASR.
This gap is exactly where S2R highlighted.
How Well Does S2R Perform?
When tested against the same SVQ dataset, S2R not only outperformed the real-world ASR cascade but also came surprisingly close to the “perfect transcription” model.
In other words, even without converting voice to text, S2R almost matched the accuracy of a flawless human-transcribed system.
This is more than a minor tweak; it is a leap forward. For users, it translates into faster, more reliable voice searches, even in noisy environments, across dialects or when using niche vocabulary.
What Is the Architecture Behind S2R?
S2R relies on a dual-encoder model:
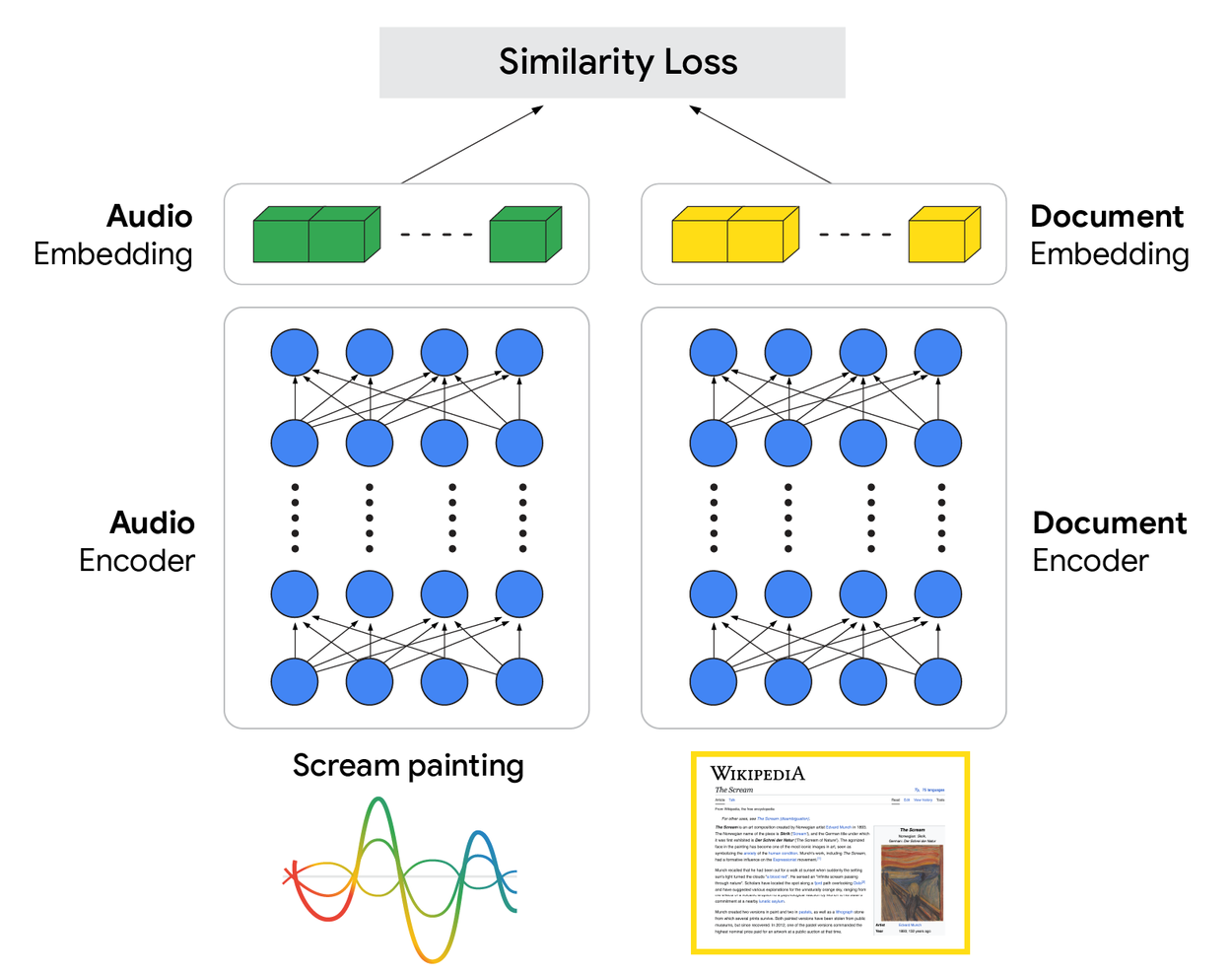
- The audio encoder learns to understand raw speech, capturing its semantic essence.
- The document encoder creates parallel embeddings for web pages.
- During training, the system learns to align query embeddings with document embeddings, bringing them “closer” in vector space when they are relevant.
This is trained on massive datasets of spoken queries paired with documents, teaching the system to connect sound directly to meaning.
Google calls this a move “from sound to meaning.” And if you think about it, that phrase sums up the entire innovation perfectly.
Why Does This Matter for Users and Businesses?
For users, the benefit is immediate: less friction and fewer errors in voice search. You can expect more accurate answers, especially in languages or regions where ASR accuracy has lagged.
For businesses, the implications are bigger. If S2R becomes the default, SEO for voice search will look very different.
Instead of optimizing for keywords that may or may not be transcribed correctly, businesses will need to ensure their content aligns with user intent at a semantic level.
Put simply: Google is shifting search from “what was said” to “what was meant.” That means clarity, structured content and contextual relevance will matter more than ever.
How Does S2R Handle Different Languages?
One of the most interesting takeaways from Google’s research is that errors don’t affect all languages equally.
In some languages, a tiny ASR error may flip meaning completely; in others, context makes it easier to recover intent. The experiments showed that Word Error Rate (WER) does not always correlate with retrieval accuracy.
S2R sidesteps this variability. By directly embedding spoken intent, it can adapt better across diverse languages and dialects. That is critical for a global product like Google Search.
What About the Open-Source Dataset?
Alongside the rollout, Google also announced the open-sourcing of the Simple Voice Questions (SVQ) dataset. Which is now part of the Massive Sound Embedding Benchmark (MSEB).
Why does this matter? Because Google is inviting researchers, developers, and academics to push this field forward.
By releasing the dataset, Google isn’t just improving its own search, it is accelerating innovation across the entire AI and speech research community.
What Comes Next for Voice Search?
S2R is already live in multiple languages. But Google admits there is still room for improvement. While it outperforms current ASR models, it has not yet fully matched the theoretical “perfect ground truth” performance.
Future work will likely focus on:
- Expanding language coverage.
- Handling long, complex voice queries.
- Combining S2R with multimodal inputs—like interpreting both your voice and an accompanying image.
- Embedding personalization to better capture user intent.
Given Google’s track record, it is safe to say this is just the beginning.

Dileep Thekkethil
AuthorDileep Thekkethil is the Director of Marketing at Stan Ventures, where he applies over 15 years of SEO and digital marketing expertise to drive growth and authority. A former journalist with six years of experience, he combines strategic storytelling with technical know-how to help brands navigate the shift toward AI-driven search and generative engines. Dileep is a strong advocate for Google’s EEAT standards, regularly sharing real-world use cases and scenarios to demystify complex marketing trends. He is an avid gardener of tropical fruits, a motor enthusiast, and a dedicated caretaker of his pair of cockatiels.